import pandas as pd
import numpy as npLecture 11 - Text Data
Overview
In this lecture, we cover:
- string manipulations in Python and pandas
- basics of regular expressions
- text analysis, including
- basic tokenization
- frequency analysis
- sentiment analysis (lexicon-based)
- topic modeling
- advanced tokenization for LLMs
- sentiment analysis (LLM-based)
References
This lecture contains material from:
- Python for Data Analysis, 3E (Wes McKinney, 2022)
Python built-in string methods
| Method | Description |
|---|---|
join |
Use string as delimiter for concatenating a sequence of other strings |
split |
Break string into list of substrings using passed delimiter |
replace |
Replace occurrences of string with another string |
strip, rstrip, lstrip |
Trim whitespace, including newlines on both sides, on the right side, or on the left side, respectively |
lower |
Convert alphabet characters to lowercase |
upper |
Convert alphabet characters to uppercase |
casefold |
Convert characters to lowercase, and convert any region-specific variable character combinations to a common comparable form |
count |
Return the number of nonoverlapping occurrences of substring in the string |
endswith |
Return True if string ends with suffix |
startswith |
Return True if string starts with prefix |
removeprefix |
Remove the passed substring from the start of the string |
removesuffix |
Remove the passed substring from the end of the string |
index |
Return starting index of the first occurrence of passed substring if found in the string; otherwise, raises ValueError if not found |
find |
Return position of first character of first occurrence of substring in the string; like index, but returns –1 if not found |
rfind |
Return position of first character of last occurrence of substring in the string; returns –1 if not found |
ljust, rjust |
Left justify or right justify, respectively; pad opposite side of string with spaces (or some other fill character) to return a string with a minimum width |
isnumeric, isalpha |
Returns true if numeric, alphabet, respectively |
From Python for Data Analysis.
Examples
' / '.join([
'first',
'second',
'third'
])'first / second / third''_joinedBy_'.join([
'first',
'second',
'third'
])'first_joinedBy_second_joinedBy_third''this is a long string with 11 parts separated by space'.split()['this',
'is',
'a',
'long',
'string',
'with',
'11',
'parts',
'separated',
'by',
'space']'we_??_can_??_also_??_split_with_??_long_strings'.split('_??_')['we', 'can', 'also', 'split_with', 'long_strings']'why would you replace this?'.replace('this', 'that')'why would you replace that?''\n please cleanup extra spaces '.strip()'please cleanup extra spaces'' please cleanup extra spaces, right only '.rstrip()' please cleanup extra spaces, right only''I AM SHOUTING no more'.lower()'i am shouting no more''Please make this more visible'.upper()'PLEASE MAKE THIS MORE VISIBLE''I AM SHOUTING no more'.casefold()'i am shouting no more'casefold and lower are mostly the same except in a few unicode characters.
Comparing strings after folding the case:
'I AM SHOUTING'.casefold() == 'I am Shouting'.casefold()TrueUse casefold instead of lower for case-insensitive string comparison. This is because casefold covers more situtations (e.g. non-English words).
'I am'.startswith('I ')True'I am foooo'.startswith('You')False'I am foooo'.casefold().startswith('i am')True'this string contains 2 times letter a'.count('a')2'16:954:597 Data Wrangling and Husbandry (3)'.removeprefix('16:954:597')' Data Wrangling and Husbandry (3)''16:954:597 Data Wrangling and Husbandry (3)'.removesuffix('(3)')'16:954:597 Data Wrangling and Husbandry 'Pandas string methods
We can access the string methods of pandas DataFrame or Series strings with .str.
| Method | Description |
|---|---|
cat |
Concatenate strings element-wise with optional delimiter |
get |
Index into each element (retrieve i-th element) |
isalpha etc. |
Equivalent to built-in str.alpha etc. |
join |
Join strings in each element of the Series with passed separator |
len |
Compute length of each string |
lower, upper |
Convert cases; equivalent to x.lower() or x.upper() for each element |
pad |
Add whitespace to left, right, or both sides of strings |
center |
Equivalent to pad(side="both") |
repeat |
Duplicate values (e.g., s.str.repeat(3) is equivalent to x * 3 for each string) |
slice |
Slice each string in the Series |
split |
Split strings on delimiter or regular expression |
strip, rstrip, lstrip |
Trim whitespace from both/right/left sides, including newlines |
From Python for Data Analysis.
The following methods take both strings and regular expressions:
| Method | Description |
|---|---|
contains |
Return Boolean array if each string contains pattern/regex |
count |
Count occurrences of pattern |
extract |
Use a regular expression with groups to extract one or more strings from a Series of strings; the result will be a DataFrame with one column per group |
endswith |
Equivalent to x.endswith(pattern) for each element |
startswith |
Equivalent to x.startswith(pattern) for each element |
findall |
Compute list of all occurrences of pattern/regex for each string |
match |
Use re.match with the passed regular expression on each element, returning True or False whether it matches |
replace |
Replace occurrences of pattern/regex with some other string |
data = {"Dave": "dave@google.com", "Steve": "steve@gmail.com", "Rob": "rob@gmail.com", "Wes": np.nan}
data = pd.Series(data)data.str.contains("gmail")Dave False
Steve True
Rob True
Wes NaN
dtype: objectRegular Expressions
Regular expressions provide a flexible way to search or match string patterns in text.
Python has built-in standard library re for applying regular expressions to strings (documentation).
Helpful resources
Basics
Letters and numbers match exactly and are called literal characters. Most punctuation characters, like ., +,*, [, ], and ?, have special meanings and are called metacharacters.
General:
[A-Z]matches one upper case letter[a-z]matches one lower case letter[a-]and[-a]matches either the letter a or the character-[A-Z][A-Z]matches two consecutive upper case letters\dor[0-9]: matches a digit\w: matches any alphanumeric character\s: matches a whitespace character (equivalent to[ \t\n\r\f\v].).: matches anything except line terminators (\n,\r,\u2028or\u2029)\b: word boundary (e.g.\bclass\bmatches class only if complete word)- More generally,
[]indicates a set of possible characters
You can use \ to escape special characters; e.g. if you want to match [, use \[
Complement:
^: match complement of the set (when in[])E.g.:
[^5]: matches any character except a 5
\D: matches any non digit character (equivalent to[^0-9])\W: matches any non-alphanumeric character (equivalent to[^a-zA-Z0-9_])\S: matches any non whitespace character (equivalent to[^ \t\n\r\f\v])
Repetitions:
+: matches the preceding pattern one or more times*: matches the preceding pattern zero or more times?: matches the preceding pattern zero or one timeE.g.:
\d+matches one or more consecutive digits\d{2,3}matches two or three consecutive digits
Beginning/end:
^: beginning of string (when not in[], e.g.^Hello)$: end of string
Groups:
(): used to specify capturing groups (e.g.(ab)*will match zero or more repetitions ofab)(?:): used to specify non-capturing groups
Logical or:
|: e.g.a|bmatchesaorb
Matching meta characters
If you’re trying to match a meta character e.g. ., $, |, *, + you can use either
- backslash escape
\.,\$, … - a character class:
[.],[$],[|]
Note: for characters with special meaning in character classes e.g. ^, you need to escape them in character class [\^].
Python functions
In Python, use the raw string notation for regular expressions:
For example:
r"[abc]"r"\\section"(to match\section)
Reason: using raw string notation avoids issues with backslashes. (Regular expressions and Python strings use backslashes '\' differently).
| Method | Description |
|---|---|
re.findall(A, B) |
Finds all non-overlapping matches of the pattern A in string B and returns them as a list. If no matches are found, it returns an empty list. |
re.finditer(A, B) |
Like findall, but returns an iterator |
re.search(A, B) |
Searches string B for the first occurrence of the pattern A and returns a match object. If no match is found, it returns None |
re.match(A, B) |
Attempts to match the pattern A starting strictly at position 0 in string B . If the pattern doesn’t match at the start, it returns None. |
re.split(A, B) |
Break string into pieces at each occurrence of pattern |
re.sub(A, B, C) |
Replaces all occurrences of the pattern A in string C with the string B and returns the modified string. The original string C remains unchanged. |
Examples
import reSplitting text
text = "foo bar\t baz \tqux"
re.split(r"\s+", text)['foo', 'bar', 'baz', 'qux']When you call re.split(r"\s+", text), the regular expression is first compiled, and then its split method is called on the passed text. You can compile the regex yourself with re.compile, forming a reusable regex object:
regex = re.compile(r"\s+")
regex.split(text)['foo', 'bar', 'baz', 'qux']Working with emails
text = """Dave dave@google.com
Steve steve@gmail.com
Rob rob@gmail.com
Ryan ryan@yahoo.com"""
pattern = r"[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4}"
# re.IGNORECASE makes the regex case insensitive
regex = re.compile(pattern, flags=re.IGNORECASE)regex.findall(text)['dave@google.com', 'steve@gmail.com', 'rob@gmail.com', 'ryan@yahoo.com']search returns a special match object for the first email address in the text:
m = regex.search(text)
m<re.Match object; span=(5, 20), match='dave@google.com'>text[m.start():m.end()]'dave@google.com'sub will return a new string with occurrences of the pattern replaced by a new string:
print(regex.sub("REDACTED", text))Dave REDACTED
Steve REDACTED
Rob REDACTED
Ryan REDACTEDSpecial characters
sentence = 'I paid $10'
# without escaping the dollar sign, nothing is found
re.search(r'$\d+', sentence) # dollar sign needs to be escaped
m = re.search(r'\$\d+', sentence)
m<re.Match object; span=(7, 10), match='$10'>sentence[m.start():m.end()]'$10'What if we want to find prices that may or may not have decimals? We can add (\.\d\d)? to specify that it can occur once, or not at all.
# dollar sign and the dot need to be escaped with a backslash
re.search(r'\$\d+(\.\d\d)?', sentence)<re.Match object; span=(7, 10), match='$10'>sentence2 = "The price is $1650.50"re.search(r'\$\d+(\.\d\d)?', sentence2)<re.Match object; span=(13, 21), match='$1650.50'>Non-capturing groups
What if we wanted to find two numbers?
sentence3 = "The price is $1650.50, or $1400 with a coupon."re.search will only return the first price:
m = re.search(r'\$\d+(\.\d\d)?', sentence3)
m<re.Match object; span=(13, 21), match='$1650.50'>sentence3[m.start():m.end()]'$1650.50're.findall will return what is in the group ( ):
re.findall(r'\$\d+(\.\d\d)?', sentence3)['.50', '']If you want the whole match, you need to use non-capturing groups, which are given by (?: ):
re.findall(r'\$\d+(?:\.\d\d)?', sentence3)['$1650.50', '$1400']Capturing an IP address in a string
An IPv4 address has the following format: x . x . x . x where x is called an octet and must be a decimal value between 0 and 255. Octets are separated by periods. An IPv4 address must contain three periods and four octets.
sentence = "my ip is given by 192.168.0.185 is that correct?"
expression = r"((?:\d{1,3}\.){3}\d{1,3})"
matches = re.findall(expression, sentence)
matches['192.168.0.185']Capturing segments of email addresses
We can use capturing groups ( ) to extract different segments of an email address:
pattern = r"([A-Z0-9._%+-]+)@([A-Z0-9.-]+)\.([A-Z]{2,4})"regex = re.compile(pattern, flags=re.IGNORECASE)m = regex.match("gm845@stat.rutgers.edu")m.groups()('gm845', 'stat.rutgers', 'edu')findall returns a list of tuples when the pattern has groups:
regex.findall("gm845@stat.rutgers.edu")[('gm845', 'stat.rutgers', 'edu')]Capturing matches in named groups
Groups can be referenced by a name.
The syntax for a named group is a Python-specific extensions: (?P<name>...)
sentence = '16:332:509 Convex Optimization for Engineering Applications (3)'sentence = '16:332:509 Convex Optimization for Engineering Applications (3)'
expression = r"(?P<school>\d{2}):(?P<level>\d{3}):(?P<course>\d{3})\s(?P<title>(\w\s?)+)\s\((?P<credits>\d+)\)"
m = re.search(expression, sentence)m.groupdict(){'school': '16',
'level': '332',
'course': '509',
'title': 'Convex Optimization for Engineering Applications',
'credits': '3'}Pandas and RegEx
data = {"Dave": "dave@google.com", "Steve": "steve@gmail.com", "Rob": "rob@gmail.com", "Wes": np.nan}
data = pd.Series(data)pattern = r"([A-Z0-9._%+-]+)@([A-Z0-9.-]+)\.([A-Z]{2,4})"data.str.findall(pattern, flags=re.IGNORECASE)Dave [(dave, google, com)]
Steve [(steve, gmail, com)]
Rob [(rob, gmail, com)]
Wes NaN
dtype: objectdata.str.findall(pattern, flags=re.IGNORECASE).str[0]Dave (dave, google, com)
Steve (steve, gmail, com)
Rob (rob, gmail, com)
Wes NaN
dtype: objectdata.str.extract(pattern, flags=re.IGNORECASE)| 0 | 1 | 2 | |
|---|---|---|---|
| Dave | dave | com | |
| Steve | steve | gmail | com |
| Rob | rob | gmail | com |
| Wes | NaN | NaN | NaN |
Text analysis
There are many analyses of text that one might want to do, including:
- Frequencies of words
- Sentiment of words
- Discovery of topics
A popular Python package for text analysis is nltk. Install it in your conda environment:
Terminal
pip install nltkTerminology
A token is a meaningful unit of text, such as a word
Tokenization is the process of splitting text into tokens.
A document-term matrix is a common format for text analysis:
- each row represents one document (e.g. a book or article)
- each column represents a term (or token)
- each cell contains the number of appearances of that term in the document
Stemming and lemmatization are techniques used to reduce words to their root forms.
Stemming is the process of removing suffixes from words such as “ed” or “ing”. For example, “jumping” would be stemmed to “jump”. Stemming can be ad-hoc and result in non-valid words.
Lemmatization is the process of reducing words to base forms, generally in a more systematic way then stemming. Lemmatization uses context to reduce words. For example, the lemma of “was” is “be”.
Stop words are words like “to”, “the”, “and” and so on, which are often removed as they are not helpful for topic modeling or sentiment analysis.
Example: Jane Austen
We study the novels of Jane Austen.
They are available for free from Project Gutenberg.
We have saved the books in the directory ../data/jane_austen.
import os
import nltkjane_dir = '../data/jane_austen'
novels = os.listdir(jane_dir)novels = [novel for novel in novels if 'csv' not in novel]
novels['prideprejudice.txt',
'persuasion.txt',
'sensesensibility.txt',
'emma.txt',
'mansfieldpark.txt',
'northangerabbey.txt']jane_dict = {}
for novel in novels:
name = novel.split('.')[0]
with open(jane_dir + '/' + novel) as file:
jane_dict[name] = file.read()The novels are saved as a single string.
print(jane_dict['prideprejudice'][0:170])PRIDE AND PREJUDICE
By Jane Austen
Chapter 1
It is a truth universally acknowledged, that a single man in possession
of a good fortune, must be in want of a wife.
book_string = jane_dict['prideprejudice']Let’s find the number of chapters.
In Jane Austen novels, chapters can be in digits or Roman numerals. Consequently, we use the regex [\divxl]+.
chapter_re = re.compile(r'\bchapter [\divxc]+', re.IGNORECASE)
chapters = re.findall(chapter_re, book_string)chapters[0:5]['Chapter 1', 'Chapter 2', 'Chapter 3', 'Chapter 4', 'Chapter 5']We can also use re.finditer to get all of the indices of the chapter matches. This can be helpful in splitting the string into chapters.
chapters = re.finditer(chapter_re, book_string)
indices = [[chapter.start(), chapter.end()] for chapter in chapters]
for i, ind in enumerate(indices):
if i < 5:
print(book_string[ind[0]:ind[1]])Chapter 1
Chapter 2
Chapter 3
Chapter 4
Chapter 5# get final indices of all chapters
chapt_split = [ind[0]-1 for i, ind in enumerate(indices) if i != 0]
# get last character of book
chapt_split.append(len(book_string))book_chapters = []
start = 0
for i, ind in enumerate(chapt_split):
book_chapters.append(
book_string[start:ind]
)
start = ind + 1Document-Term Matrix
sklearn has a convenient function CountVectorizer:
- input: a list of documents
- output: a document-term-matrix
CountVectorizer uses a very simple tokenization - it removes punctuation and keeps only words with more than two characters.
from sklearn.feature_extraction.text import CountVectorizer# chapter-term matrix
vectorizer = CountVectorizer()
dtm = vectorizer.fit_transform(book_chapters)We obtain the words using vectorizer.get_feature_names_out():
words = vectorizer.get_feature_names_out()We use .toarray() to obtain the word counts:
dtm_df = pd.DataFrame(dtm.toarray(), columns=words)dtm_df| 10 | 11 | 12 | 13 | 14 | 15 | 15th | 16 | 17 | 18 | ... | young | younge | younger | youngest | your | yours | yourself | yourselves | youth | youths | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 2 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 1 | 0 | 0 | 2 | 5 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 4 | 0 | 0 | 0 | 4 | 0 | 1 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 2 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 3 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 56 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 4 | 0 | 0 | 0 | 6 | 0 | 3 | 0 | 0 | 0 |
| 57 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 22 | 1 | 2 | 0 | 0 | 0 |
| 58 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 2 | 0 | 0 | 0 | 9 | 0 | 3 | 0 | 0 | 0 |
| 59 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 1 | 0 | 0 | 0 | 16 | 3 | 3 | 0 | 0 | 0 |
| 60 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 |
61 rows × 6432 columns
We can see that there are a number of words like “youth” and “youths” which we may want to stem or lemmatize.
For now, let’s look at the top word count.
book_count = dtm_df.sum()
book_count.sort_values(ascending=False).head()the 4331
to 4162
of 3610
and 3585
her 2203
dtype: int64Stop words
We can see that the most common words are stop words like “to”, “the”, “and” and so on.
We can give a list of stop words to CountVectorizer to ignore.
We will use the stop words from the tidytext R package. They have been processed and stored as stop_words.csv.
stop_csv = pd.read_csv(jane_dir + '/stop_words.csv')vectorizer = CountVectorizer(stop_words=stop_csv['word'].to_list())
dtm = vectorizer.fit_transform(book_chapters)
words = vectorizer.get_feature_names_out()dtm_df = pd.DataFrame(dtm.toarray(), columns=words)book_count = dtm_df.sum()
book_count.sort_values(ascending=False).head()elizabeth 635
darcy 417
bennet 323
bingley 306
jane 292
dtype: int64import seaborn as sns
import matplotlib.pyplot as plt
plot_df = book_count.sort_values(ascending=False).to_frame()
plot_df = plot_df.reset_index()
plot_df.columns = ['word', 'count']
plot_df = plot_df[plot_df['count'] > 150]
sns.catplot(plot_df,
x='count',
y='word',
kind='bar')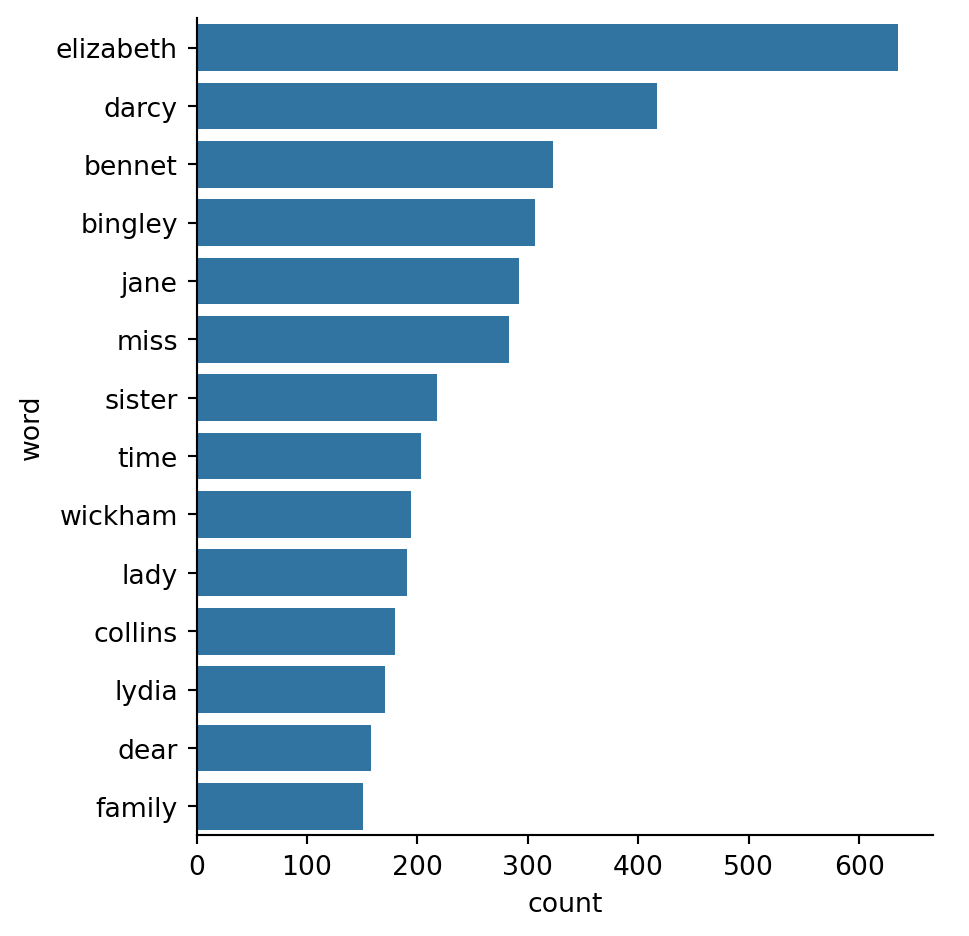
Bigrams
We can also look at bigrams - pairs of words that co-occur.
nltk.download('punkt_tab')[nltk_data] Downloading package punkt_tab to /Users/gm845/nltk_data...
[nltk_data] Package punkt_tab is already up-to-date!Truefrom nltk import FreqDistWe use CountVectorizer’s tokenization to tokenize the words. This is a simple regex: (?u)\b\w\w+\b.
(?u): flag that makes\winclude unicode letters (equivalent tore.UNICODE)\b: word boundary\b\w\w+\b: keep only words with more than two characters
regex = re.compile(r'(?u)\b\w\w+\b')
tokens = re.findall(regex, book_string.lower()) Now we remove stop words:
stop_words = set(stop_csv['word'])
tokens = [t for t in tokens if t not in stop_words]bigram_list = list(nltk.bigrams(tokens))fdist = FreqDist(bigram_list)
print(fdist.most_common(5)) # top 5 bigrams[(('lady', 'catherine'), 116), (('miss', 'bingley'), 87), (('miss', 'bennet'), 65), (('sir', 'william'), 44), (('miss', 'darcy'), 39)]bigram_df = pd.DataFrame(fdist.items(), columns = ['bigram', 'count'])bigram_df.sort_values(by='count', ascending=False).head(10)| bigram | count | |
|---|---|---|
| 5454 | (lady, catherine) | 116 |
| 676 | (miss, bingley) | 87 |
| 753 | (miss, bennet) | 65 |
| 113 | (sir, william) | 44 |
| 5456 | (de, bourgh) | 39 |
| 3192 | (miss, darcy) | 39 |
| 15472 | (colonel, fitzwilliam) | 30 |
| 1843 | (colonel, forster) | 28 |
| 885 | (miss, lucas) | 25 |
| 3091 | (cried, elizabeth) | 24 |
bigram_df['bigram'] = bigram_df['bigram'].map(lambda x: ' '.join(x))plot_df = bigram_df[bigram_df['count'] > 20].sort_values(by='count', ascending=False)sns.catplot(plot_df,
x='count',
y='bigram',
kind='bar')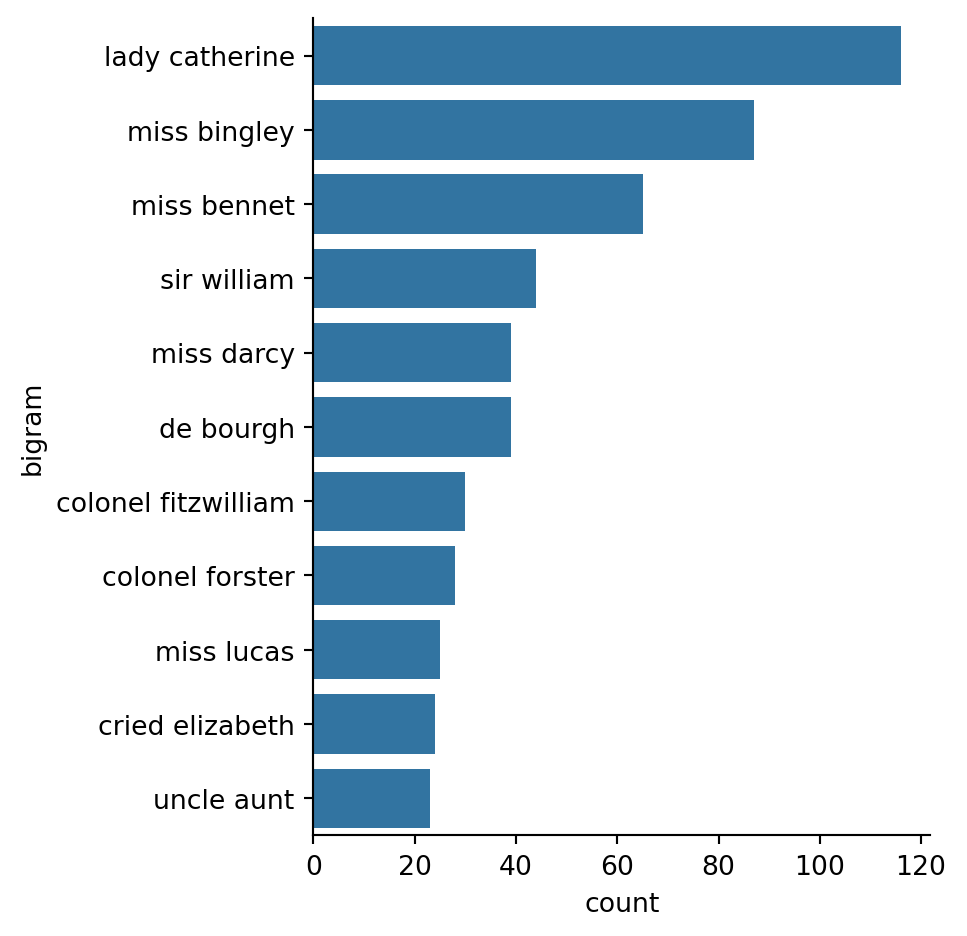
Example: The Brown Corpus
The Brown Corpus was the first million-word electronic corpus of English, created in 1961 at Brown University. This corpus contains text from 500 sources, and the sources have been categorized by genre, such as news, editorial, and so on. (For a full list, see here).
The complete list of data available on NLTK is here.
nltk.download('brown')[nltk_data] Downloading package brown to /Users/gm845/nltk_data...
[nltk_data] Package brown is already up-to-date!Truefrom nltk.corpus import brown
brown.categories()['adventure',
'belles_lettres',
'editorial',
'fiction',
'government',
'hobbies',
'humor',
'learned',
'lore',
'mystery',
'news',
'religion',
'reviews',
'romance',
'science_fiction']scifi = brown.words(categories='science_fiction')
adventure = brown.words(categories='adventure')Let’s use the simple tokenization (more than two characters, removing punctuation).
regex = re.compile(r'(?u)\b\w\w+\b')scifi = [w.lower() for w in scifi if re.fullmatch(regex, w) and w.lower() not in stop_words]
adventure = [w.lower() for w in adventure if re.fullmatch(regex, w) and w.lower() not in stop_words]scifi_dist = nltk.FreqDist(w for w in scifi)
adv_dist = nltk.FreqDist(w for w in adventure)scifi_dist.items()dict_items([('free', 3), ('grok', 5), ('closer', 6), ('brothers', 4), ('merge', 2), ('integrity', 1), ('mike', 20), ('stopped', 3), ('cherish', 2), ('brother', 6), ('mars', 9), ('corporate', 1), ('discorporate', 2), ('precious', 1), ('earth', 15), ('unknown', 1), ('powers', 2), ('waiting', 2), ('grokked', 4), ('cherished', 3), ('remained', 2), ('trance', 2), ('loose', 1), ('puzzle', 1), ('fit', 1), ('growing', 6), ('heard', 4), ('archangel', 3), ('foster', 5), ('tabernacle', 1), ('cusp', 2), ('digby', 7), ('bishop', 4), ('senator', 1), ('boone', 2), ('warily', 1), ('uneasy', 1), ('miss', 2), ('dawn', 1), ('ardent', 1), ('tasted', 1), ('water', 7), ('smell', 1), ('goodness', 3), ('incompletely', 1), ('jumping', 2), ('wailing', 1), ('conversations', 1), ('coming', 2), ('words', 8), ('troubled', 1), ('studied', 1), ('compared', 2), ('taught', 6), ('nestling', 1), ('struggling', 1), ('bridge', 1), ('languages', 2), ('learning', 2), ('word', 6), ('church', 3), ('knotty', 1), ('difficulty', 1), ('martian', 4), ('concept', 6), ('match', 2), ('worship', 1), ('god', 5), ('congregation', 1), ('equated', 1), ('totality', 1), ('world', 6), ('forced', 5), ('english', 4), ('phrase', 2), ('rejected', 1), ('jubal', 9), ('mahmoud', 2), ('thou', 3), ('art', 4), ('understanding', 1), ('inevitability', 1), ('stood', 5), ('mind', 15), ('spoke', 9), ('simultaneously', 2), ('sentence', 1), ('grokking', 4), ('repeating', 1), ('student', 1), ('telling', 2), ('jewel', 1), ('lotus', 1), ('sank', 1), ('nirvana', 1), ('midnight', 3), ('speeded', 1), ('heart', 2), ('resumed', 1), ('normal', 5), ('breathing', 3), ('ran', 2), ('check', 4), ('list', 2), ('uncurled', 1), ('sat', 3), ('weary', 1), ('light', 13), ('gay', 1), ('ready', 4), ('actions', 1), ('spreading', 1), ('puppyish', 1), ('company', 3), ('strong', 4), ('earlier', 1), ('necessity', 2), ('quiet', 2), ('stepped', 2), ('hall', 1), ('delighted', 1), ('encounter', 1), ('chipper', 1), ('feel', 4), ('fine', 4), ('asleep', 3), ('ben', 1), ('stinky', 1), ('home', 3), ('hour', 1), ('ago', 6), ('people', 23), ('started', 3), ('bed', 1), ('disappointed', 1), ('left', 5), ('explain', 1), ('snack', 1), ('hungry', 2), ('cold', 2), ('chicken', 1), ('downstairs', 1), ('loaded', 1), ('tray', 3), ('lavishly', 1), ('plenty', 2), ('warm', 5), ('idea', 2), ('agreed', 5), ('swim', 1), ('real', 5), ('indian', 1), ('summer', 2), ('switch', 4), ('floods', 1), ('bother', 2), ('answered', 4), ('carry', 3), ('total', 3), ('darkness', 1), ('conditions', 2), ('grown', 3), ('true', 2), ('parents', 1), ('night', 10), ('comfortable', 2), ('naked', 3), ('mount', 1), ('everest', 1), ('tolerance', 1), ('temperature', 1), ('pressure', 3), ('considerate', 1), ('weakness', 1), ('learned', 3), ('forward', 1), ('snow', 2), ('tiny', 3), ('crystal', 1), ('life', 5), ('unique', 2), ('individual', 1), ('read', 6), ('walking', 1), ('barefoot', 1), ('rolling', 1), ('meantime', 2), ('pleased', 3), ('pleasing', 1), ('underwater', 1), ('lights', 1), ('eat', 3), ('ripples', 1), ('beauty', 1), ('picnicked', 1), ('pool', 1), ('lay', 9), ('grass', 2), ('looked', 7), ('stars', 4), ('antares', 1), ('hesitated', 3), ('question', 4), ('wide', 2), ('sparse', 1), ('language', 3), ('horizon', 2), ('southern', 4), ('hemisphere', 4), ('spring', 1), ('plants', 4), ('grow', 5), ('larry', 1), ('teaches', 1), ('helped', 2), ('martians', 3), ('teach', 2), ('colder', 1), ('nymphs', 1), ('stayed', 4), ('alive', 4), ('brought', 2), ('nests', 1), ('quickening', 1), ('humans', 2), ('equator', 1), ('discorporated', 1), ('sad', 3), ('news', 2), ('booker', 1), ('jones', 1), ('food', 2), ('technician', 1), ('class', 4), ('dark', 3), ('beautiful', 6), ('homesick', 3), ('dear', 3), ('lonely', 6), ('rolled', 2), ('arms', 2), ('darling', 1), ('kissed', 1), ('kissing', 1), ('presently', 1), ('breathlessly', 1), ('worse', 1), ('time', 34), ('kiss', 1), ('cosmic', 2), ('clock', 1), ('merged', 1), ('softly', 1), ('triumphantly', 1), ('answer', 3), ('voice', 9), ('called', 7), ('25', 1), ('building', 1), ('domes', 1), ('male', 1), ('female', 3), ('party', 4), ('arrive', 1), ('ship', 20), ('faster', 2), ('scheduled', 1), ('helpful', 1), ('saved', 1), ('spent', 2), ('preliminary', 1), ('estimate', 1), ('plan', 2), ('bound', 2), ('oxygen', 3), ('sands', 1), ('planet', 10), ('friendly', 1), ('future', 3), ('human', 5), ('generations', 3), ('hindered', 1), ('meditations', 1), ('approaching', 1), ('violent', 2), ('shape', 1), ('millennia', 1), ('elections', 1), ('continued', 2), ('advanced', 1), ('poet', 1), ('published', 2), ('limited', 2), ('edition', 1), ('verse', 1), ('consisting', 1), ('punctuation', 1), ('marks', 1), ('spaces', 1), ('magazine', 1), ('reviewed', 1), ('suggested', 3), ('federation', 2), ('assembly', 1), ('daily', 1), ('record', 1), ('translated', 2), ('medium', 2), ('colossal', 1), ('campaign', 1), ('sell', 1), ('sexual', 1), ('organs', 3), ('joseph', 1), ('shadow', 2), ('greatness', 1), ('douglas', 1), ('quoted', 1), ('sit', 2), ('flowers', 2), ('table', 1), ('serviettes', 1), ('tibetan', 1), ('swami', 1), ('palermo', 1), ('sicily', 1), ('announced', 3), ('beverly', 1), ('hills', 1), ('newly', 1), ('discovered', 5), ('ancient', 2), ('yoga', 1), ('discipline', 1), ('ripple', 1), ('increased', 1), ('pranha', 1), ('attraction', 1), ('sexes', 1), ('chelas', 1), ('required', 3), ('assume', 1), ('matsyendra', 1), ('posture', 1), ('dressed', 1), ('diapers', 1), ('aloud', 1), ('assistant', 1), ('guru', 1), ('examined', 1), ('purses', 1), ('stolen', 1), ('purpose', 1), ('president', 1), ('united', 3), ('proclaimed', 1), ('sunday', 1), ('november', 1), ('national', 1), ('day', 8), ('urged', 1), ('america', 5), ('funeral', 1), ('parlor', 1), ('chain', 2), ('indicted', 1), ('fosterite', 1), ('bishops', 2), ('secret', 5), ('conclave', 1), ('major', 2), ('miracle', 2), ('supreme', 4), ('bodily', 1), ('heaven', 2), ('ranking', 1), ('glorious', 3), ('held', 3), ('pending', 1), ('heavenly', 1), ('confirmation', 1), ('elevation', 2), ('huey', 1), ('short', 6), ('candidate', 2), ('accepted', 2), ('faction', 1), ('lots', 2), ('cast', 2), ('repeatedly', 1), ('hoy', 1), ('identical', 1), ('denunciations', 1), ('romano', 1), ('christian', 1), ('science', 1), ('monitor', 2), ('times', 2), ('india', 4), ('snickered', 1), ('manchester', 1), ('guardian', 2), ('simply', 5), ('reported', 3), ('fosterites', 1), ('england', 1), ('extremely', 1), ('militant', 1), ('promotion', 1), ('interrupted', 1), ('half', 10), ('finished', 1), ('stupid', 3), ('jackass', 2), ('louse', 1), ('listened', 2), ('angelic', 2), ('patience', 1), ('listen', 2), ('junior', 2), ('angel', 8), ('forget', 2), ('eternity', 1), ('recriminations', 1), ('poisoned', 1), ('popes', 1), ('warts', 1), ('promoted', 2), ('ahead', 1), ('professional', 2), ('jealousy', 1), ('calmed', 1), ('request', 1), ('shook', 2), ('halo', 2), ('touch', 3), ('submit', 1), ('requisition', 1), ('fool', 2), ('understand', 4), ('system', 5), ('setup', 2), ('run', 4), ('universe', 3), ('variety', 1), ('field', 5), ('workers', 1), ('punk', 1), ('brush', 1), ('hold', 3), ('helping', 1), ('boss', 1), ('performance', 2), ('gripes', 1), ('calm', 2), ('duck', 1), ('muslim', 1), ('paradise', 1), ('straighten', 1), ('square', 2), ('wings', 1), ('dig', 1), ('sooner', 1), ('act', 1), ('quicker', 1), ('happy', 10), ('heaved', 1), ('deep', 2), ('ethereal', 1), ('sigh', 2), ('start', 3), ('hear', 2), ('disappearance', 3), ('fleeting', 1), ('suspicion', 5), ('dismissed', 1), ('finger', 1), ('happened', 4), ('worried', 2), ('bothered', 1), ('household', 1), ('upset', 1), ('deduced', 1), ('inquire', 1), ('legal', 1), ('age', 3), ('presumed', 1), ('defend', 1), ('clinches', 1), ('boy', 2), ('salted', 1), ('reconstruct', 1), ('crime', 1), ('girls', 2), ('behaved', 1), ('patterns', 2), ('shifting', 1), ('abc', 1), ('bcd', 1), ('ab', 1), ('cd', 1), ('ad', 1), ('cb', 1), ('women', 3), ('gang', 1), ('week', 1), ('trip', 3), ('period', 4), ('pronounced', 1), ('dead', 7), ('minded', 1), ('service', 3), ('pieces', 1), ('spend', 1), ('tiptoeing', 1), ('preoccupied', 1), ('cook', 1), ('secretaries', 1), ('anne', 3), ('hell', 3), ('worst', 1), ('subject', 3), ('unexplained', 1), ('tears', 2), ('bet', 1), ('witness', 1), ('memorize', 1), ('date', 1), ('personae', 1), ('events', 3), ('barometric', 1), ('batting', 1), ('blue', 2), ('eyes', 9), ('expense', 1), ('involved', 2), ('astronomical', 1), ('vessel', 4), ('interstellar', 1), ('drives', 1), ('hundred', 3), ('found', 9), ('live', 7), ('inhabited', 2), ('sentient', 2), ('hal', 23), ('forgetting', 1), ('enthusiasm', 1), ('speak', 4), ('macneff', 7), ('pacing', 1), ('stare', 1), ('pale', 1), ('sharply', 1), ('forgive', 2), ('sandalphon', 3), ('inevitable', 2), ('forerunner', 4), ('predict', 1), ('line', 3), ('page', 1), ('573', 1), ('smiled', 7), ('glad', 1), ('scriptural', 1), ('lessons', 4), ('impression', 1), ('impressions', 1), ('bear', 1), ('scars', 1), ('pornsen', 3), ('gapt', 7), ('whipped', 1), ('impresser', 1), ('grew', 1), ('creche', 1), ('dormitory', 1), ('college', 1), ('block', 1), ('responsible', 3), ('low', 4), ('swiftly', 2), ('revulsion', 1), ('protest', 1), ('die', 6), ('willed', 1), ('sigmen', 4), ('pardon', 1), ('expedition', 6), ('records', 3), ('swift', 1), ('survey', 1), ('return', 3), ('distance', 2), ('lightyears', 1), ('star', 4), ('eye', 1), ('volunteer', 2), ('told', 3), ('leaves', 2), ('linguist', 3), ('huge', 2), ('military', 1), ('specialists', 1), ('taking', 1), ('limits', 1), ('linguists', 1), ('considered', 1), ('professionals', 1), ('lamechians', 1), ('waited', 1), ('paced', 1), ('frowning', 1), ('lamechian', 1), ('exists', 2), ('thousand', 3), ('pardons', 1), ('married', 3), ('aboard', 2), ('gabriel', 10), ('automatically', 2), ('divorce', 4), ('gasped', 1), ('raised', 1), ('hands', 7), ('apologetically', 1), ('horrified', 2), ('reading', 3), ('western', 2), ('talmud', 1), ('urielites', 1), ('knowing', 3), ('situation', 4), ('arise', 1), ('reference', 1), ('provision', 2), ('couple', 1), ('separated', 1), ('forty', 1), ('naturally', 2), ('couched', 1), ('obscure', 1), ('wisdom', 2), ('enemies', 1), ('israelites', 1), ('planned', 1), ('months', 6), ('yarrow', 4), ('observation', 2), ('dome', 2), ('watched', 3), ('ball', 1), ('dwindle', 1), ('blazed', 1), ('megalopolises', 1), ('australia', 2), ('japan', 2), ('china', 3), ('southeast', 2), ('asia', 3), ('siberia', 2), ('glittering', 1), ('discs', 1), ('necklaces', 1), ('terms', 2), ('spoken', 1), ('philippine', 1), ('islands', 2), ('northern', 3), ('haijac', 2), ('union', 3), ('american', 3), ('ceylon', 1), ('malay', 1), ('bazaar', 1), ('icelandic', 1), ('globe', 1), ('visualized', 1), ('africa', 1), ('swahili', 1), ('south', 3), ('sahara', 1), ('sea', 2), ('mediterranean', 1), ('minor', 2), ('tibet', 1), ('hebrew', 1), ('native', 3), ('tongue', 2), ('europe', 2), ('israeli', 2), ('republics', 2), ('peoples', 2), ('thin', 3), ('stretch', 1), ('territory', 1), ('march', 1), ('land', 2), ('disputed', 1), ('republic', 1), ('potential', 1), ('source', 1), ('war', 4), ('nation', 3), ('claim', 1), ('wished', 1), ('move', 2), ('lead', 3), ('apocalyptic', 2), ('practical', 1), ('purposes', 2), ('independent', 1), ('organized', 1), ('government', 2), ('unrecognized', 1), ('borders', 1), ('citizens', 2), ('surviving', 1), ('tongues', 1), ('lingo', 1), ('pidgin', 1), ('vocabulary', 1), ('derived', 1), ('syntax', 2), ('simple', 2), ('contained', 1), ('sheet', 1), ('paper', 1), ('rest', 2), ('iceland', 2), ('greenland', 1), ('caribbean', 1), ('eastern', 1), ('island', 1), ('jump', 4), ('busy', 2), ('resettling', 1), ('north', 2), ('speech', 5), ('twenty', 1), ('descendants', 1), ('living', 3), ('hudson', 1), ('bay', 1), ('preserve', 1), ('rotated', 1), ('zone', 1), ('city', 1), ('blaze', 1), ('space', 7), ('enormous', 2), ('apartment', 1), ('mary', 5), ('notified', 1), ('days', 4), ('husband', 2), ('died', 3), ('accident', 3), ('flight', 2), ('tahiti', 1), ('weep', 1), ('private', 1), ('loved', 2), ('frigid', 1), ('public', 3), ('friends', 1), ('associates', 1), ('sympathize', 1), ('lost', 8), ('beloved', 2), ('unrealistically', 1), ('killed', 4), ('crash', 1), ('passengers', 1), ('supposed', 1), ('web', 3), ('elaborate', 1), ('frauds', 1), ('cover', 1), ('personnel', 6), ('disgrace', 1), ('cremated', 1), ('ashes', 1), ('flung', 1), ('winds', 2), ('ceremony', 1), ('fish', 1), ('bodies', 10), ('sturch', 2), ('cared', 1), ('keeping', 1), ('welling', 1), ('crowd', 2), ('tear', 1), ('rend', 1), ('mutual', 1), ('torture', 1), ('marry', 1), ('secretly', 1), ('thinking', 3), ('death', 2), ('dissolved', 1), ('marriage', 2), ('choose', 1), ('mate', 1), ('selected', 2), ('psychological', 2), ('barriers', 1), ('prevented', 1), ('conceiving', 1), ('child', 1), ('doubted', 1), ('event', 1), ('occur', 1), ('frozen', 5), ('navel', 1), ('matter', 6), ('fat', 1), ('whining', 3), ('slowly', 2), ('feeling', 2), ('icy', 1), ('burning', 1), ('squat', 1), ('smiling', 1), ('lopsidedly', 1), ('ward', 2), ('perennial', 1), ('gadfly', 1), ('voyage', 1), ('love', 4), ('foreseen', 1), ('choking', 1), ('wonderful', 2), ('destination', 2), ('acceleration', 3), ('build', 2), ('ultimate', 1), ('velocity', 1), ('percent', 1), ('speed', 3), ('suspensor', 2), ('lie', 2), ('suspended', 2), ('animation', 2), ('automatic', 2), ('equipment', 3), ('crew', 3), ('join', 1), ('sleep', 5), ('drive', 4), ('increase', 1), ('unfrozen', 2), ('endured', 2), ('reaching', 2), ('desired', 1), ('cut', 3), ('silent', 1), ('empty', 3), ('hurl', 1), ('apparatus', 1), ('nose', 1), ('determine', 1), ('close', 3), ('actuate', 1), ('deceleration', 2), ('force', 1), ('endure', 1), ('applied', 2), ('slowing', 1), ('considerably', 1), ('adjust', 1), ('unthaw', 1), ('preparations', 1), ('study', 1), ('recordings', 2), ('chief', 1), ('ozagen', 4), ('siddo', 7), ('faced', 3), ('difficult', 3), ('task', 1), ('succeeded', 1), ('correlating', 1), ('equal', 2), ('description', 1), ('restricted', 1), ('mistaken', 2), ('discovery', 1), ('caused', 1), ('anxiety', 1), ('duty', 2), ('write', 4), ('school', 3), ('text', 1), ('entire', 1), ('means', 1), ('disposal', 1), ('instructing', 1), ('students', 1), ('wrongly', 1), ('natives', 1), ('differed', 1), ('sounds', 4), ('dissimilar', 1), ('approximated', 1), ('ozagenians', 1), ('approximations', 1), ('obstacle', 1), ('grammatical', 1), ('construction', 1), ('tense', 3), ('inflecting', 1), ('verb', 1), ('unattached', 1), ('particle', 1), ('past', 3), ('masculine', 2), ('animate', 1), ('infinitive', 1), ('meaning', 3), ('perfect', 3), ('tenses', 1), ('earthmen', 5), ('genders', 1), ('feminine', 1), ('neuter', 1), ('extra', 2), ('inanimate', 1), ('spiritual', 1), ('fortunately', 1), ('gender', 2), ('inflected', 1), ('expression', 1), ('born', 1), ('indicating', 1), ('varied', 1), ('nouns', 1), ('pronouns', 1), ('adjectives', 1), ('adverbs', 1), ('conjunctions', 1), ('operated', 1), ('verbs', 1), ('running', 3), ('logical', 2), ('deductive', 1), ('deciding', 1), ('action', 1), ('established', 1), ('premise', 1), ('doubt', 2), ('angels', 10), ('fast', 4), ('computer', 4), ('basic', 3), ('assumptions', 2), ('govern', 1), ('motives', 1), ('wholly', 1), ('reasoning', 3), ('process', 2), ('takes', 2), ('fixed', 1), ('millions', 1), ('reason', 4), ('pause', 2), ('jack', 18), ('snapping', 2), ('answers', 1), ('questions', 2), ('wait', 2), ('dice', 1), ('misjudged', 1), ('concluded', 1), ('race', 2), ('ephemeral', 1), ('develop', 3), ('sense', 5), ('justice', 1), ('races', 3), ('galactic', 1), ('center', 5), ('individually', 1), ('mortal', 1), ('difference', 1), ('marked', 1), ('survived', 2), ('periods', 1), ('recommend', 1), ('shorten', 1), ('trial', 1), ('wrong', 5), ('reclaim', 1), ('property', 3), ('penalty', 1), ('hesperus', 11), ('lifted', 1), ('perceive', 1), ('essential', 2), ('distinction', 1), ('practicing', 1), ('deal', 2), ('agent', 1), ('nature', 2), ('agreement', 4), ('regard', 1), ('fair', 2), ('feels', 1), ('received', 2), ('valuable', 2), ('pounding', 1), ('instance', 2), ('individuals', 1), ('bargaining', 1), ('nations', 2), ('treaty', 6), ('mission', 1), ('nest', 1), ('mine', 1), ('recovering', 1), ('strange', 5), ('apparently', 2), ('impossible', 1), ('lucifer', 2), ('pleasure', 4), ('curiosity', 1), ('commodities', 1), ('nursery', 6), ('visiting', 1), ('offering', 1), ('worth', 3), ('explained', 1), ('gladly', 1), ('entertain', 1), ('proper', 4), ('quarters', 2), ('fusion', 5), ('reactors', 1), ('accordance', 2), ('customs', 1), ('misuse', 1), ('power', 7), ('hurt', 3), ('requires', 1), ('behave', 1), ('dictates', 1), ('natures', 2), ('respect', 2), ('agree', 2), ('wave', 1), ('complete', 3), ('elation', 1), ('vanished', 2), ('trace', 2), ('mankind', 3), ('forego', 1), ('parochial', 1), ('moral', 1), ('judgments', 1), ('contract', 1), ('serve', 2), ('applicable', 2), ('laws', 2), ('exercise', 1), ('similar', 1), ('restraints', 1), ('natural', 1), ('preferences', 2), ('faintest', 1), ('notion', 1), ('perverse', 1), ('habit', 1), ('passing', 2), ('enforcing', 1), ('contrary', 1), ('violations', 1), ('principle', 4), ('ratify', 1), ('trust', 2), ('uncomfortable', 2), ('custom', 1), ('absolutes', 1), ('proposal', 1), ('amount', 2), ('declaration', 1), ('highly', 1), ('trained', 2), ('law', 2), ('clerk', 1), ('codified', 1), ('experience', 4), ('safest', 1), ('sanest', 1), ('attitude', 2), ('outsiders', 1), ('precedent', 1), ('history', 4), ('disarmament', 1), ('agreements', 2), ('unreassuringly', 1), ('dismal', 1), ('soviet', 1), ('socialist', 1), ('eventually', 4), ('atomic', 2), ('bomb', 1), ('test', 1), ('ban', 1), ('sort', 2), ('provisional', 1), ('acceptance', 1), ('intentions', 1), ('easy', 4), ('road', 1), ('emerged', 2), ('hegemony', 1), ('existed', 1), ('virulence', 1), ('rivalry', 1), ('arizona', 1), ('california', 1), ('supplies', 1), ('petty', 1), ('details', 1), ('thrashed', 1), ('commonplace', 1), ('diplomatic', 2), ('trouble', 3), ('historically', 1), ('sign', 1), ('quarrel', 1), ('settled', 1), ('suppose', 3), ('faith', 2), ('convinced', 1), ('tentative', 1), ('final', 3), ('signed', 1), ('secretary', 1), ('hart', 1), ('partially', 1), ('content', 2), ('beginnings', 1), ('matters', 1), ('handle', 1), ('screens', 1), ('crucial', 1), ('conclusive', 1), ('lips', 2), ('late', 1), ('audience', 1), ('moment', 3), ('riot', 1), ('color', 3), ('meaningless', 1), ('activity', 1), ('gradually', 1), ('realized', 1), ('pentagon', 1), ('elders', 3), ('ritual', 1), ('dance', 1), ('broken', 1), ('zigzagging', 1), ('wildly', 1), ('directions', 1), ('seemingly', 1), ('random', 1), ('instruments', 1), ('range', 2), ('scanned', 3), ('skies', 2), ('boards', 2), ('pip', 1), ('radar', 2), ('bigger', 2), ('rapidly', 1), ('skiff', 6), ('unprecedented', 1), ('hove', 1), ('sight', 5), ('dot', 1), ('roiling', 1), ('blackness', 1), ('crimson', 1), ('streaks', 1), ('coal', 2), ('sack', 2), ('telescope', 1), ('spacesuits', 1), ('attached', 1), ('sail', 2), ('unfurled', 1), ('holes', 1), ('langer', 3), ('predicted', 1), ('startling', 1), ('numenous', 1), ('awesome', 1), ('trailing', 1), ('heading', 1), ('ariadne', 2), ('chance', 1), ('signaling', 1), ('nernst', 2), ('generator', 3), ('send', 2), ('call', 1), ('powerful', 3), ('static', 1), ('rebuild', 1), ('fuming', 1), ('helpless', 1), ('pass', 1), ('ragged', 1), ('surface', 4), ('catch', 2), ('ocean', 1), ('poured', 1), ('believed', 1), ('bizarre', 2), ('causing', 1), ('agitation', 1), ('refused', 1), ('fed', 2), ('plots', 1), ('curve', 1), ('card', 1), ('spat', 1), ('argued', 1), ('headed', 3), ('nebula', 1), ('core', 1), ('religion', 1), ('attract', 1), ('attention', 2), ('equally', 1), ('stern', 1), ('chase', 1), ('10', 1), ('surely', 1), ('set', 4), ('frighteningly', 1), ('observant', 1), ('talked', 1), ('decided', 2), ('cloud', 1), ('meant', 6), ('invade', 1), ('holy', 1), ('holies', 1), ('direction', 1), ('intentional', 2), ('unnecessary', 1), ('outcome', 1), ('disastrous', 1), ('crawled', 1), ('restored', 1), ('feet', 5), ('excised', 1), ('reinstall', 1), ('fuses', 2), ('triggered', 1), ('receiving', 1), ('promised', 1), ('intercept', 2), ('deeper', 1), ('obstruct', 1), ('bargain', 1), ('hearth', 1), ('promptly', 1), ('admitted', 4), ('incident', 1), ('angry', 2), ('permitted', 1), ('relief', 2), ('plugged', 1), ('threw', 2), ('transition', 1), ('green', 1), ('winked', 1), ('board', 4), ('minutes', 3), ('hotter', 1), ('cruiser', 1), ('dreamed', 1), ('failed', 1), ('anticipate', 1), ('plotting', 1), ('orbit', 1), ('vector', 1), ('trick', 1), ('ryan', 14), ('hefted', 1), ('bulk', 1), ('supported', 1), ('elbow', 1), ('rubbed', 1), ('sleepily', 2), ('paw', 1), ('ekstrohm', 26), ('nogol', 8), ('guys', 2), ('cured', 1), ('cure', 1), ('explaining', 1), ('black', 3), ('darted', 1), ('inside', 2), ('olive', 1), ('oval', 1), ('insisted', 1), ('country', 1), ('facsiport', 1), ('landscape', 1), ('bluffs', 1), ('hugged', 1), ('decaying', 1), ('moss', 1), ('sky', 3), ('winter', 1), ('minneapolis', 1), ('fire', 1), ('magnification', 2), ('galaxy', 1), ('milky', 1), ('blown', 1), ('master', 1), ('photographer', 1), ('fiery', 1), ('swath', 1), ('belt', 2), ('planets', 2), ('asteroid', 1), ('original', 2), ('solar', 2), ('capable', 1), ('holding', 2), ('atmosphere', 4), ('infuriation', 1), ('scientists', 1), ('mapping', 1), ('planetoids', 1), ('nearest', 1), ('continent', 1), ('antarctica', 1), ('neighbors', 1), ('captain', 8), ('elaborately', 1), ('helmets', 1), ('breathe', 2), ('helium', 1), ('gases', 2), ('nitrogen', 1), ('animals', 2), ('ringing', 1), ('intelligent', 2), ('hostile', 1), ('interjected', 1), ('quietly', 2), ('readings', 1), ('sonic', 2), ('electronic', 1), ('galvanic', 1), ('blank', 1), ('needles', 1), ('stone', 2), ('fort', 1), ('confirmed', 1), ('story', 1), ('rookie', 1), ('excited', 1), ('encephalographic', 1), ('officer', 1), ('unfathomable', 1), ('manner', 1), ('dials', 1), ('lug', 1), ('remember', 4), ('hand', 3), ('straight', 2), ('negative', 2), ('positive', 1), ('results', 2), ('mark', 1), ('ambidextrous', 1), ('airlock', 1), ('glance', 2), ('lapel', 1), ('gauge', 2), ('coverall', 2), ('suit', 1), ('repel', 1), ('bacteria', 1), ('insects', 2), ('types', 1), ('infection', 1), ('attack', 1), ('mammal', 1), ('infinite', 1), ('adequate', 1), ('defenses', 1), ('categories', 1), ('hot', 1), ('chills', 1), ('puzzling', 1), ('striped', 1), ('fever', 1), ('ladder', 1), ('seismological', 1), ('judge', 1), ('resistance', 1), ('dropped', 1), ('ground', 6), ('contrasts', 1), ('sharp', 1), ('walked', 3), ('noon', 2), ('beast', 1), ('sprawled', 1), ('nudged', 2), ('boot', 1), ('hey', 1), ('pretty', 2), ('matches', 1), ('happen', 5), ('statistical', 1), ('average', 1), ('creepy', 1), ('rabbit', 1), ('turtle', 1), ('makes', 1), ('exploration', 2), ('business', 1), ('joke', 2), ('surveyor', 2), ('sidewise', 1), ('seldom', 1), ('cleared', 1), ('throat', 3), ('dissect', 1), ('toe', 1), ('stormy', 3), ('dominant', 1), ('species', 1), ('definite', 1), ('proof', 1), ('clearer', 1), ('picture', 2), ('ecological', 1), ('beasts', 1), ('represent', 1), ('blastdown', 1), ('landing', 1), ('lethal', 1), ('creatures', 1), ('radiation', 3), ('mineral', 1), ('deposits', 1), ('shield', 1), ('output', 1), ('dose', 1), ('knock', 1), ('critters', 2), ('virtually', 1), ('radioactive', 1), ('exposure', 1), ('stored', 1), ('lot', 1), ('harm', 1), ('shockwave', 1), ('sheer', 1), ('xenophobia', 1), ('curl', 1), ('alien', 3), ('spaceship', 2), ('stage', 1), ('game', 2), ('possibility', 2), ('aliens', 1), ('hope', 3), ('sudden', 2), ('bunk', 6), ('camp', 4), ('leave', 2), ('sleeping', 3), ('solid', 2), ('cluster', 1), ('aluminum', 1), ('bubbles', 2), ('ringed', 1), ('spy', 1), ('alert', 1), ('approach', 1), ('bubble', 3), ('privacy', 2), ('enforced', 1), ('intimacy', 1), ('138', 1), ('keening', 1), ('wind', 1), ('cracking', 1), ('revive', 1), ('thaw', 1), ('morning', 2), ('sun', 2), ('couches', 1), ('soundly', 1), ('renewed', 1), ('contact', 1), ('birthed', 1), ('riding', 2), ('vacuum', 1), ('pretending', 2), ('blanket', 1), ('swung', 1), ('floor', 1), ('hide', 4), ('changed', 4), ('closed', 2), ('walk', 1), ('comfort', 1), ('insomnia', 3), ('slept', 3), ('doctors', 1), ('informed', 2), ('shortly', 1), ('fitfully', 1), ('forgot', 2), ('absolutely', 1), ('correct', 2), ('body', 6), ('processes', 1), ('slowed', 1), ('dispell', 1), ('fatigue', 1), ('poisons', 1), ('occasionally', 1), ('fell', 2), ('waking', 2), ('stupor', 2), ('shipmates', 1), ('physiological', 1), ('grounds', 1), ('buddies', 2), ('confide', 1), ('invariably', 1), ('advantage', 1), ('stand', 2), ('watches', 1), ('reports', 1), ('threatening', 1), ('report', 1), ('laxness', 1), ('avoid', 1), ('bad', 1), ('dreams', 1), ('shipboard', 1), ('hiding', 2), ('easier', 1), ('hard', 1), ('picked', 1), ('lightweight', 1), ('library', 2), ('book', 1), ('bloch', 1), ('famous', 1), ('twentieth', 1), ('century', 2), ('expert', 1), ('sex', 2), ('lines', 1), ('social', 1), ('repercussions', 1), ('celebrated', 1), ('nineteenth', 1), ('murderer', 1), ('concentrate', 1), ('weighty', 1), ('pontifical', 1), ('ponderous', 1), ('style', 1), ('impulse', 1), ('flipped', 1), ('heat', 1), ('control', 5), ('slid', 1), ('hatch', 2), ('glass', 1), ('unfamiliar', 1), ('constellations', 1), ('smelling', 1), ('sterility', 1), ('air', 1), ('mates', 1), ('stirred', 2), ('startled', 1), ('banging', 1), ('resting', 3), ('sleeplessly', 1), ('greeted', 1), ('fun', 1), ('games', 2), ('beasties', 1), ('laying', 1), ('talking', 2), ('shouldered', 1), ('veldt', 1), ('ring', 1), ('animal', 1), ('corpses', 1), ('wispy', 1), ('whipping', 1), ('keen', 1), ('breeze', 1), ('damned', 1), ('buddy', 1), ('expe', 1), ('mucking', 1), ('primary', 1), ('evidence', 1), ('demanded', 2), ('pick', 1), ('patsy', 1), ('local', 1), ('phenomenon', 1), ('accuse', 1), ('shipmate', 1), ('benefit', 1), ('model', 1), ('pink', 4), ('ticket', 1), ('fits', 1), ('pattern', 1), ('secrecy', 1), ('stealth', 1), ('lousy', 1), ('alarm', 1), ('tapes', 2), ('missing', 1), ('explanations', 1), ('pull', 1), ('deliberately', 1), ('foul', 1), ('head', 15), ('mental', 2), ('illness', 1), ('scowled', 1), ('outweigh', 1), ('fifty', 1), ('pounds', 1), ('planning', 1), ('lived', 3), ('helva', 26), ('vegetable', 1), ('waved', 2), ('crabbed', 1), ('claws', 1), ('kicked', 1), ('weakly', 1), ('clubbed', 1), ('enjoyed', 3), ('usual', 1), ('routine', 1), ('infant', 1), ('children', 3), ('special', 1), ('removed', 1), ('central', 10), ('laboratory', 4), ('delicate', 1), ('transformation', 1), ('babies', 1), ('initial', 2), ('transferral', 1), ('seventeen', 1), ('thrived', 1), ('metal', 2), ('shells', 5), ('kicking', 1), ('neural', 3), ('responses', 1), ('wheels', 1), ('grabbing', 1), ('manipulated', 1), ('mechanical', 1), ('extensions', 1), ('matured', 1), ('synapses', 1), ('adjusted', 1), ('operate', 1), ('mechanisms', 1), ('maintenance', 1), ('destined', 1), ('brain', 9), ('scout', 5), ('partnered', 1), ('woman', 4), ('whichever', 1), ('chose', 2), ('mobile', 2), ('elite', 1), ('intelligence', 2), ('tests', 2), ('registered', 1), ('adaptation', 1), ('index', 1), ('unusually', 1), ('development', 2), ('shell', 11), ('expectations', 1), ('pituitary', 2), ('tinkering', 1), ('rewarding', 1), ('rich', 1), ('unusual', 2), ('cry', 1), ('ordinary', 1), ('diagram', 1), ('recorded', 2), ('learn', 1), ('bide', 1), ('official', 1), ('trusting', 1), ('massive', 1), ('doses', 1), ('suffice', 1), ('bulwark', 1), ('confinement', 1), ('pressures', 1), ('profession', 2), ('rogue', 1), ('insane', 1), ('resources', 1), ('ships', 3), ('experimental', 1), ('stages', 1), ('babes', 1), ('techniques', 3), ('manipulation', 1), ('eliminating', 1), ('transfers', 1), ('larger', 1), ('connection', 1), ('panels', 2), ('industrial', 1), ('combine', 1), ('resembled', 1), ('mature', 1), ('dwarfs', 1), ('size', 1), ('natal', 1), ('deformities', 1), ('scooted', 1), ('classmates', 1), ('playing', 1), ('stall', 1), ('studying', 1), ('trajectory', 1), ('propulsion', 1), ('computation', 1), ('logistics', 1), ('hygiene', 1), ('psychology', 1), ('philology', 1), ('traffic', 1), ('codes', 1), ('ceteras', 1), ('compounded', 1), ('citizen', 1), ('obvious', 1), ('importance', 1), ('teachers', 1), ('ingested', 1), ('precepts', 1), ('conditioning', 1), ('easily', 1), ('absorbed', 1), ('nutrient', 1), ('fluid', 1), ('grateful', 1), ('patient', 1), ('drone', 1), ('instruction', 1), ('civilization', 1), ('associations', 1), ('exploring', 1), ('inhumanities', 1), ('terrestrial', 1), ('extraterrestrial', 1), ('incensed', 1), ('shelled', 1), ('fourteen', 1), ('worlds', 2), ('shrugged', 1), ('shoulders', 1), ('arranged', 1), ('tour', 2), ('schools', 1), ('histories', 1), ('photographs', 1), ('committees', 1), ('photos', 1), ('objections', 1), ('overridden', 1), ('hideous', 1), ('mercifully', 1), ('concealed', 1), ('arts', 1), ('selective', 1), ('crowded', 1), ('program', 2), ('activated', 1), ('microscopic', 1), ('tools', 1), ('minute', 1), ('repairs', 1), ('panel', 1), ('copy', 3), ('supper', 3), ('canvas', 1), ('screw', 3), ('tuned', 1), ('degree', 1), ('absentmindedly', 1), ('crooned', 2), ('producing', 1), ('curious', 5), ('sound', 5), ('vocal', 3), ('cords', 1), ('diaphragms', 1), ('issued', 1), ('microphones', 1), ('mouths', 1), ('hum', 2), ('vibrancy', 1), ('dulcet', 1), ('quality', 2), ('aimless', 1), ('chromatic', 1), ('wanderings', 1), ('lovely', 1), ('visitors', 1), ('caught', 1), ('fascinating', 1), ('panorama', 1), ('regular', 1), ('dirty', 1), ('craters', 1), ('flaky', 1), ('gurgle', 1), ('surprise', 1), ('instinctively', 2), ('regulated', 1), ('skin', 2), ('cratered', 1), ('pores', 1), ('assumed', 1), ('proportions', 1), ('training', 1), ('madam', 1), ('remarked', 3), ('calmly', 2), ('peculiarities', 1), ('excessively', 1), ('irritating', 1), ('prolonged', 1), ('distances', 1), ('eliminated', 1), ('unshelled', 1), ('reaction', 1), ('instantly', 1), ('nice', 5), ('singing', 3), ('lady', 11), ('amended', 1), ('politely', 2), ('sheered', 1), ('personal', 1), ('discussions', 2), ('filed', 1), ('comment', 1), ('meditation', 1), ('reproducing', 1), ('twittered', 1), ('vision', 2), ('surveyed', 1), ('critically', 1), ('values', 1), ('perspective', 1), ('faulty', 1), ('unmagnified', 1), ('bugged', 1), ('contrite', 1), ('blushed', 1), ('adjustable', 1), ('discourse', 1), ('grinned', 1), ('pride', 1), ('amusement', 1), ('tone', 2), ('pity', 1), ('unfortunate', 1), ('substituting', 1), ('magnifying', 1), ('device', 1), ('extension', 1), ('shock', 1), ('ladies', 2), ('gentlemen', 1), ('committee', 2), ('bent', 1), ('observe', 1), ('incredibly', 1), ('copied', 1), ('brilliantly', 1), ('executed', 1), ('gentleman', 1), ('accompany', 1), ('wife', 1), ('lord', 1), ('fear', 1), ('tread', 1), ('referring', 1), ('sir', 2), ('pin', 2), ('substitute', 1), ('atom', 1), ('insoluble', 1), ('metallic', 1), ('programed', 1), ('compute', 1), ('humor', 2), ('directed', 1), ('proportion', 1), ('contributes', 1), ('effect', 1), ('chortled', 1), ('appreciatively', 1), ('investigation', 1), ('digesting', 1), ('thoughtful', 1), ('served', 1), ('morsel', 1), ('research', 1), ('exposed', 1), ('music', 2), ('appreciation', 1), ('included', 1), ('classical', 1), ('tristan', 1), ('und', 1), ('isolde', 1), ('candide', 1), ('oklahoma', 1), ('nozze', 1), ('de', 1), ('figaro', 1), ('singers', 2), ('eileen', 1), ('farrell', 1), ('elvis', 1), ('presley', 1), ('geraldine', 1), ('todd', 1), ('rhythmic', 1), ('progressions', 1), ('venusians', 1), ('capellan', 1), ('visual', 2), ('chromatics', 1), ('concerti', 1), ('altairians', 1), ('person', 1), ('posed', 1), ('considerable', 1), ('technical', 2), ('difficulties', 1), ('overcome', 1), ('schooled', 1), ('examine', 1), ('aspect', 1), ('prognosis', 1), ('balanced', 1), ('properly', 1), ('optimism', 1), ('practicality', 1), ('nondefeatist', 1), ('led', 1), ('extricate', 1), ('situations', 1), ('mouth', 1), ('sing', 4), ('restrictions', 1), ('method', 1), ('limitations', 1), ('approached', 1), ('investigating', 1), ('methods', 1), ('reproduction', 3), ('centuries', 1), ('instrumental', 2), ('production', 1), ('essentially', 1), ('breath', 1), ('enunciation', 1), ('vowel', 2), ('oral', 2), ('cavity', 3), ('appeared', 1), ('require', 1), ('practice', 1), ('strictly', 1), ('speaking', 1), ('drawn', 1), ('surrounding', 1), ('lungs', 1), ('sustained', 1), ('artificially', 1), ('solution', 1), ('experimentation', 1), ('manipulate', 1), ('diaphragmic', 2), ('unit', 1), ('sustain', 1), ('relaxing', 1), ('muscles', 1), ('expanding', 1), ('frontal', 1), ('sinuses', 1), ('direct', 1), ('felicitous', 1), ('position', 2), ('microphone', 1), ('tape', 1), ('modern', 1), ('unpleased', 1), ('peculiar', 1), ('unharmonious', 1), ('acquiring', 1), ('repertoire', 1), ('recall', 1), ('role', 1), ('song', 1), ('struck', 2), ('fancy', 1), ('occurred', 2), ('bass', 1), ('baritone', 1), ('tenor', 1), ('alto', 1), ('mezzo', 1), ('soprano', 1), ('coloratura', 1), ('attempted', 1), ('authorities', 1), ('avocation', 1), ('encouraged', 1), ('hobby', 1), ('maintained', 1), ('proficiency', 1), ('anniversary', 1), ('sixteenth', 1), ('unconditionally', 1), ('graduated', 1), ('installed', 1), ('aj', 1), ('permanent', 1), ('titanium', 1), ('recessed', 1), ('indestructible', 1), ('barrier', 1), ('shaft', 1), ('audio', 1), ('sensory', 1), ('connections', 1), ('sealed', 1), ('extendibles', 1), ('diverted', 1), ('connected', 1), ('augmented', 1), ('taps', 1), ('completed', 1), ('anesthetically', 1), ('unaware', 1), ('proceedings', 1), ('awoke', 1), ('controlled', 1), ('function', 1), ('navigation', 1), ('loading', 1), ('care', 2), ('ambulatory', 1), ('annals', 1), ('fertile', 1), ('minds', 1), ('imagine', 1), ('actual', 3), ('mock', 1), ('flights', 1), ('dummy', 1), ('mastery', 1), ('adventures', 1), ('arrival', 1), ('partner', 3), ('qualified', 1), ('scouts', 1), ('sitting', 2), ('collecting', 1), ('base', 2), ('pay', 1), ('commissioned', 1), ('missions', 1), ('instant', 1), ('department', 1), ('heads', 1), ('determined', 1), ('assigned', 1), ('section', 1), ('remembered', 3), ('introduce', 1), ('prospective', 1), ('partners', 2), ('guided', 1), ('wrangled', 1), ('robert', 1), ('tanner', 2), ('sneaked', 1), ('barracks', 1), ('slim', 1), ('hull', 1), ('wisecracked', 1), ('replied', 1), ('logically', 1), ('activating', 1), ('scanners', 1), ('recognized', 2), ('uniform', 1), ('retorted', 1), ('directives', 2), ('sounded', 1), ('truth', 2), ('darkened', 1), ('recently', 1), ('technicians', 1), ('score', 1), ('solitude', 1), ('momentary', 1), ('charm', 1), ('oppressive', 1), ('scarcely', 1), ('regret', 1), ('biting', 1), ('fingernails', 1), ('quick', 1), ('invitation', 1), ('cabin', 4), ('mercer', 26), ('stammered', 1), ('baby', 1), ('noticed', 3), ('needle', 4), ('arm', 1), ('knot', 1), ('hit', 2), ('hug', 1), ('spacesuit', 1), ('stumbled', 1), ('girl', 2), ('covered', 2), ('radiated', 1), ('warmth', 1), ('fellowship', 1), ('distinguished', 1), ('charming', 1), ('struggled', 1), ('clothes', 1), ('foolish', 1), ('snobbish', 1), ('wear', 1), ('clothing', 1), ('babbled', 1), ('corner', 2), ('expressing', 1), ('euphoria', 1), ('drug', 5), ('forbidden', 1), ('wondered', 3), ('luck', 2), ('visit', 1), ('da', 7), ('painful', 1), ('stab', 1), ('abdomen', 1), ('pain', 7), ('swallowed', 1), ('cap', 1), ('hospital', 1), ('crippling', 1), ('deliberate', 1), ('rammed', 1), ('focus', 1), ('pinkly', 1), ('nude', 1), ('desert', 1), ('bite', 1), ('foremost', 1), ('upright', 1), ('talk', 3), ('forever', 3), ('happiness', 5), ('thicken', 1), ('slack', 1), ('awake', 1), ('companionable', 1), ('attractive', 1), ('sterilizing', 1), ('knives', 1), ('lasted', 1), ('ministrations', 1), ('dromozoa', 5), ('screams', 1), ('movement', 1), ('agonies', 1), ('nerves', 1), ('itching', 1), ('phenomena', 1), ('remote', 3), ('casual', 1), ('dragged', 1), ('arrived', 2), ('blinked', 1), ('friendlily', 1), ('lapsed', 1), ('restful', 1), ('rise', 1), ('occasion', 1), ('briefly', 1), ('shining', 1), ('mysterious', 1), ('canceled', 1), ('cycles', 1), ('inwardness', 1), ('pains', 2), ('shayol', 4), ('benign', 1), ('torsos', 2), ('stretched', 1), ('capacity', 1), ('retaining', 1), ('condition', 1), ('articulate', 1), ('arteries', 1), ('pulsating', 1), ('prettily', 1), ('film', 1), ('protected', 1), ('abdominal', 1), ('squeezed', 1), ('shoulder', 1), ('woke', 1), ('healthily', 1), ('sleepy', 1), ('grin', 1), ('morrow', 1), ('play', 3), ('cards', 1), ('figures', 1), ('ashamed', 1), ('obviousness', 1), ('plays', 1), ('dummies', 1), ('gestured', 1), ('hummocks', 1), ('decorticated', 1), ('cradled', 1), ('scene', 3), ('laughed', 1), ('lovelies', 1), ('clocks', 1), ('cares', 1), ('count', 2), ('calendars', 1), ('climate', 1), ('inclined', 1), ('conviction', 1), ('dromozootic', 1), ('implant', 1), ('red', 1), ('shouted', 1), ('senselessly', 1), ('helplessly', 1), ('twisted', 1), ('dusty', 2), ('wept', 2), ('hoarsely', 1), ('moved', 1), ('father', 1), ('clustered', 1), ('pleasantly', 1), ('thigh', 2), ('hair', 1), ('top', 1), ('dainty', 1), ('eyebrows', 1), ('blissful', 1), ('knife', 1), ('grinding', 1), ('cartilage', 1), ('grimace', 1), ('cool', 1), ('flash', 1), ('unimportant', 1), ('dabbed', 1), ('wound', 1), ('corrosive', 1), ('antiseptic', 1), ('bleeding', 1), ('immediately', 1), ('legs', 2), ('chest', 1), ('torso', 1), ('waist', 1), ('teratologies', 1), ('shapely', 1), ('nicest', 1), ('relationship', 1), ('whisper', 1), ('repeated', 2), ('thousands', 1), ('smiles', 1), ('immensely', 1), ('comforting', 1), ('victims', 1), ('appearance', 1), ('everlasting', 1), ('brains', 1), ('added', 1), ('herds', 1), ('truck', 1), ('threshed', 1), ('bawled', 1), ('finally', 1), ('manage', 1), ('follow', 2), ('door', 1), ('fight', 1), ('bliss', 1), ('memory', 1), ('previous', 1), ('bewilderment', 1), ('perplexity', 1), ('fighting', 1), ('begged', 1), ('grudgingly', 1), ('doorway', 1), ('address', 1), ('box', 1), ('built', 1), ('gigantic', 1), ('roared', 1), ('plain', 3), ('herd', 2), ('gently', 2), ('friend', 1), ('exceedingly', 1), ('profound', 1), ('understood', 1), ('standard', 1), ('hours', 1), ('eleven', 1), ('fellow', 1), ('sane', 1), ('persuaded', 1), ('remain', 1), ('crazy', 1), ('slave', 1), ('hopes', 1), ('surrounded', 1), ('family', 1), ('resembling', 1), ('fate', 2), ('eaten', 1), ('eggs', 1), ('pan', 1), ('staggered', 1), ('hospitable', 1), ('unclaimed', 1), ('miles', 1), ('seating', 1), ('appreciated', 1), ('kindliness', 1), ('gesture', 1), ('change', 2), ('bubbling', 1), ('geysers', 1), ('faintly', 1), ('declared', 1), ('alvarez', 1), ('setting', 1), ('crops', 1), ('season', 1), ('load', 1), ('commingled', 1), ('shocks', 1), ('statement', 1), ('wit', 1), ('courses', 1), ('exchange', 1), ('names', 1), ('harvest', 1), ('dream', 1), ('escape', 1), ('chemical', 1), ('rockets', 1), ('lift', 1), ('plans', 1), ('crop', 1), ('transmuted', 1), ('flesh', 1), ('prisoner', 1), ('letter', 2), ('handwriting', 1), ('rock', 1), ('scraped', 1), ('message', 1), ('stepping', 1), ('window', 1), ('letting', 1), ('blow', 1), ('ten', 1), ('fingers', 1), ('front', 1)])scifi_df = pd.DataFrame(scifi_dist.items(), columns = ['word', 'count'])
adv_df = pd.DataFrame(adv_dist.items(), columns = ['word', 'count'])# normalize counts
scifi_df['count_norm'] = scifi_df['count'] / scifi_df['count'].sum()
adv_df['count_norm'] = adv_df['count'] / adv_df['count'].sum()merge_df = pd.merge(scifi_df, adv_df, left_on='word', right_on='word')merge_df.sort_values(by=['count_norm_x', 'count_norm_y'], ascending=False).head()| word | count_x | count_norm_x | count_y | count_norm_y | |
|---|---|---|---|---|---|
| 165 | time | 34 | 0.008026 | 129 | 0.006189 |
| 80 | people | 23 | 0.005430 | 24 | 0.001152 |
| 3 | mike | 20 | 0.004721 | 28 | 0.001343 |
| 175 | ship | 20 | 0.004721 | 1 | 0.000048 |
| 542 | jack | 18 | 0.004249 | 23 | 0.001104 |
import plotly.express as px
fig = px.scatter(
merge_df,
x='count_norm_x',
y='count_norm_y',
hover_data=['word'],
log_x=True,
log_y=True,
height=400,
width=600
)
fig.update_layout(
title="Word Frequency Scatterplot",
xaxis_title="SciFi Normalized Count",
yaxis_title="Adventure Normalized Count",
)
fig.show()Sentiment Analysis
When we read a section of text, we infer what feelings the section conveys, such as:
- Joy/Sadness
- Positive/Negative
- Anger
- Anticipation
- Disgust
- Fear
- Surprise
- Trust
Sentiment analysis is an attempt to extract the sentiment, or feeling or attitude, from text.
Lexicon-based analysis
A sentiment lexicon is a list of lexical features (e.g. words) which are labelled according to their sentiment (e.g. positive/negative, or a score).
Lexicon-based sentiment analysis compares words to the sentiment lexicon.
We consider two lexicon-based analyses:
- NRC
- VADER
Alternatives to lexicon-based analyses are machine learning based sentiment analyses.
NRC
The NRC Emotion Lexicon is a list of English words and their associations with eight basic emotions (anger, fear, anticipation, trust, surprise, sadness, joy, and disgust) and two sentiments (negative and positive).
References
- Crowdsourcing a Word-Emotion Association Lexicon, Saif Mohammad and Peter Turney, Computational Intelligence, 29 (3), 436-465, 2013.
nrc = pd.read_csv('../data/nrc/NRC-Emotion-Lexicon-Wordlevel-v0.92.txt', sep='\t', header=None)nrc.columns = ['word', 'sentiment', 'indicator']nrc[nrc['indicator'] == 1].head(10)| word | sentiment | indicator | |
|---|---|---|---|
| 19 | abacus | trust | 1 |
| 23 | abandon | fear | 1 |
| 25 | abandon | negative | 1 |
| 27 | abandon | sadness | 1 |
| 30 | abandoned | anger | 1 |
| 33 | abandoned | fear | 1 |
| 35 | abandoned | negative | 1 |
| 37 | abandoned | sadness | 1 |
| 40 | abandonment | anger | 1 |
| 43 | abandonment | fear | 1 |
nrc = nrc[nrc['indicator'] == 1]
nrc = nrc.drop(columns='indicator')nrc['sentiment'].unique()array(['trust', 'fear', 'negative', 'sadness', 'anger', 'surprise',
'positive', 'disgust', 'joy', 'anticipation'], dtype=object)Let’s analyze a book by Jane Austen.
- Split by line
book_string = jane_dict['prideprejudice']
book_lines = book_string.split('\n')- Remove empty lines
book_lines = [line for line in book_lines if len(line) > 0]len(book_lines)10721- We will need the chapter numbers - this is how we can find the chapters:
chapter_number = re.compile(r'\bchapter [\divxlc]+', re.IGNORECASE)
m = re.findall(chapter_number, book_string)- We import some useful NLTK functions
import nltk
nltk.download('wordnet')
nltk.download('stopwords')
nltk.download('averaged_perceptron_tagger_eng')
from nltk.corpus import stopwords, wordnet
from nltk.stem import WordNetLemmatizer
from nltk import pos_tag, word_tokenize
stops = set(stopwords.words('english'))
lemmatizer = WordNetLemmatizer()
# Helper to convert treebank POS to WordNet POS
def get_wordnet_pos(tag):
if tag.startswith('J'):
return wordnet.ADJ
elif tag.startswith('V'):
return wordnet.VERB
elif tag.startswith('N'):
return wordnet.NOUN
elif tag.startswith('R'):
return wordnet.ADV
else:
return wordnet.NOUN # fallback[nltk_data] Downloading package wordnet to /Users/gm845/nltk_data...
[nltk_data] Package wordnet is already up-to-date!
[nltk_data] Downloading package stopwords to /Users/gm845/nltk_data...
[nltk_data] Package stopwords is already up-to-date!
[nltk_data] Downloading package averaged_perceptron_tagger_eng to
[nltk_data] /Users/gm845/nltk_data...
[nltk_data] Package averaged_perceptron_tagger_eng is already up-to-
[nltk_data] date!Let’s see an example of tokenization and lemmatization.
book_lines[5]'However little known the feelings or views of such a man may be on his'We:
- tokenize each line
- get the part-of-speech for each token (details here)
- lemmatize the word, using the part-of-speech tag as an input to the lemmatizer
Part-of-speech tag
Why do we get the POS tag?
lemmatizer.lemmatize('has')returns
'ha'This is because the lemmatizer defaults to a noun (it treats it as “ha has”, for example).
Instead:
lemmatizer.lemmatize('has', wordnet.VERB)returns
'have'tokens = word_tokenize(book_lines[5])
tagged = pos_tag(tokens)
lemmatized = [lemmatizer.lemmatize(word, get_wordnet_pos(tag)) for word, tag in tagged]
lemmatized['However',
'little',
'know',
'the',
'feeling',
'or',
'view',
'of',
'such',
'a',
'man',
'may',
'be',
'on',
'his']We now create a table with:
- line number
- chapter number
- word
We also remove stop words and punctuation.
book_list = []
current_chapter = 0
punctuation = '!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'
for i, line in enumerate(book_lines):
# increase chapter number if we find a chapter
current_chapter += len(re.findall(chapter_number, line))
# tokenize
tokens = word_tokenize(line)
tagged = pos_tag(tokens)
tokens = [lemmatizer.lemmatize(word, get_wordnet_pos(tag)) for word, tag in tagged]
# keep tokens that are not punctuation or stop words; also, return lower case
tokens = [token.lower() for token in tokens if token not in punctuation and token not in stops]
for token in tokens:
book_list.append({
'line_number': i,
'chapter_number': current_chapter,
'word': token
})book_df = pd.DataFrame(book_list)Now, let’s add the sentiment of each word.
book_sent = pd.merge(book_df, nrc, on='word')Let’s look at just the “joy” words.
book_joy = book_sent.loc[book_sent['sentiment'] == 'joy']
book_joy = book_joy.groupby('word').size()book_joy = pd.DataFrame(book_joy, columns=['count'])book_joy.sort_values(by='count', ascending=False).head(10)| count | |
|---|---|
| word | |
| good | 231 |
| friend | 166 |
| hope | 143 |
| mother | 134 |
| daughter | 133 |
| feeling | 109 |
| love | 105 |
| marry | 105 |
| happy | 91 |
| happiness | 72 |
Let’s track the sentiment over the course of the novel
- We will first add an index for every certain number of lines
import math
book_sent['index'] = (book_sent['line_number'] / 80).apply(math.floor)- Next, count how many words of each sentiment in each chunk of the book
book_time = book_sent.groupby(['index', 'sentiment']).size().to_frame()book_time = book_time.reset_index()book_time.rename(columns={0: 'count'}, inplace=True)Normalize based on number of words in index:
- first, get number of words in each index
- second, merge the index counts back to main df
- third, divide word count by index count
index_count = pd.DataFrame(book_time.groupby('index')['count'].sum())index_count.rename(columns={'count': 'index_count'}, inplace=True)book_time = pd.merge(book_time, index_count, left_on='index', right_index=True)book_time['norm_count'] = book_time['count'] / book_time['index_count']book_time| index | sentiment | count | index_count | norm_count | |
|---|---|---|---|---|---|
| 0 | 0 | anger | 8 | 207 | 0.038647 |
| 1 | 0 | anticipation | 25 | 207 | 0.120773 |
| 2 | 0 | disgust | 7 | 207 | 0.033816 |
| 3 | 0 | fear | 13 | 207 | 0.062802 |
| 4 | 0 | joy | 26 | 207 | 0.125604 |
| ... | ... | ... | ... | ... | ... |
| 1334 | 133 | negative | 27 | 293 | 0.092150 |
| 1335 | 133 | positive | 78 | 293 | 0.266212 |
| 1336 | 133 | sadness | 8 | 293 | 0.027304 |
| 1337 | 133 | surprise | 14 | 293 | 0.047782 |
| 1338 | 133 | trust | 49 | 293 | 0.167235 |
1339 rows × 5 columns
sns.relplot(book_time,
x='index',
y='norm_count',
hue='sentiment',
col='sentiment',
col_wrap=2,
kind='line',
aspect=1.5,
height=3)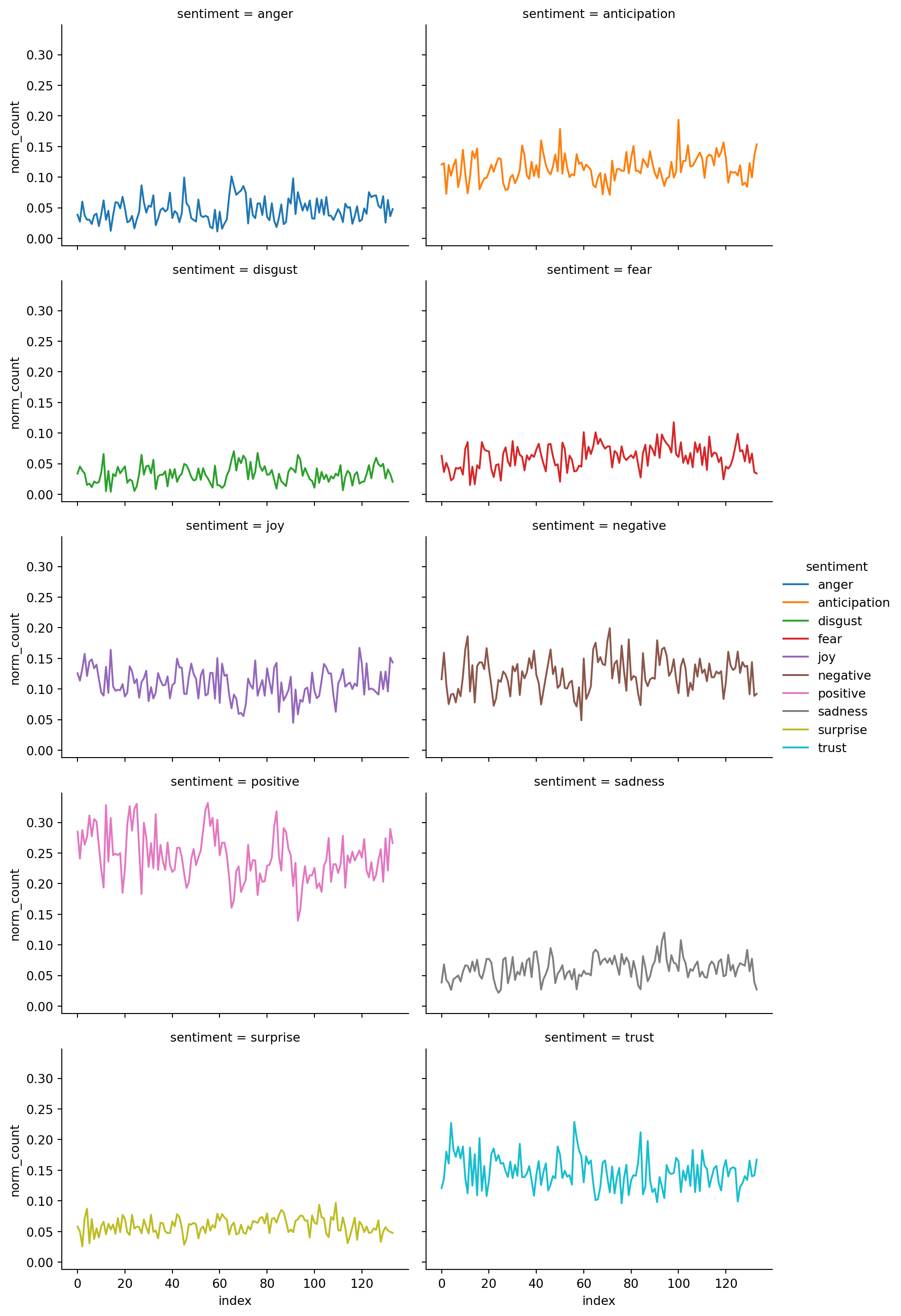
VADER
NLTK comes with a sentiment analyzer called VADER — great for social media, short text, or general tone. VADER has a set of pre-defined rules based on lexical features to determine sentiment.
We will take a look at this large movie review dataset (Maas et al. 2011).
References
- Hutto, C.J. & Gilbert, E.E. (2014). VADER: A Parsimonious Rule-based Model for Sentiment Analysis of Social Media Text. Eighth International Conference on Weblogs and Social Media (ICWSM-14). Ann Arbor, MI, June 2014.
- Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. (2011). Learning Word Vectors for Sentiment Analysis. The 49th Annual Meeting of the Association for Computational Linguistics (ACL 2011).
nltk.download('vader_lexicon')[nltk_data] Downloading package vader_lexicon to
[nltk_data] /Users/gm845/nltk_data...
[nltk_data] Package vader_lexicon is already up-to-date!Truefrom nltk.sentiment.vader import SentimentIntensityAnalyzer
sia = SentimentIntensityAnalyzer()We have stored a subset of the reviews in ../data/imdb-reviews with one text file per review.
review_list = []
files = os.listdir('../data/imdb-reviews/')
for file in files:
with open('../data/imdb-reviews/' + file) as review:
review_list.append(review.read())Example:
review_list[1]'Oh dear. I watched this film because a colleague recommended it. I will have serious words with her next time I see her. Here\'s why...<br /><br />A good film can be let down by a moment in the film when you, the viewer, don\'t believe (or buy) the characters\' decisions or actions. This happened in The Wrestler, when the main character \'forgot\' to attend the dinner date that he had managed to arrange with his estranged daughter. However, I would say on balance that The Wrestler is a good film, as other aspects of the film compensated for this \'moment\'.<br /><br />Right At Your Door, on the other hand is literally riddled with moments which made me question the characters\' actions and decisions to the point that I was saying out loud, phrases beginning with "Why did he just...?" or "Why doesn\'t she...?" This kind of spoilt the viewing experience for me.<br /><br />Also, I can\'t say that on balance, in spite of these numerous confusing/irritating moments, that RAYD is a good film. As many have said, the idea is good, but the script is really weak. The \'twist\' at the end of the film left me furious. I really did feel like I had wasted 90 minutes of my life. I wanted all the characters to die of the poison - along with anyone who had anything to do with the relaxation of this cinematic sludge.<br /><br />And yet, there are people and critics who rate this film quite highly. Perhaps you should see it for yourself, but by no means do that under my recommendation.'We remove HTML tags, but keep all other punctuation etc.
review_proc = []
for review in review_list:
review = review.replace("<br", "")
review = review.replace(r"/>", "")
review_proc.append(review)VADER returns four scores:
neg: negative sentimentneu: neutral sentimentpos: positive sentimentcompound: aggregation of neg/neu/pos scores
From the documentation:
The
pos,neu, andnegscores are ratios for proportions of text that fall in each categoryThe
compoundscore is computed by summing the valence scores of each word, adjusted according to the rules, and then normalized to be between -1 (most extreme negative) and +1 (most extreme positive). This is the most useful metric if you want a single unidimensional measure of sentiment for a given sentence.
score = sia.polarity_scores(review_proc[1])
print(score){'neg': 0.116, 'neu': 0.809, 'pos': 0.075, 'compound': -0.9494}review_scores = []
for review in review_proc:
score = sia.polarity_scores(review)
review_scores.append({
'review': review,
'pos': score['pos'],
'neu': score['neu'],
'neg': score['neg'],
'compound': score['compound']
})review_df = pd.DataFrame(review_scores)review_df = review_df.sort_values(by='pos', ascending=False)
for i in range(5):
print(review_df['review'].iloc[i])I loved this movie! Mistress Hughes is charming and true, Ned is perfect, I could well understand _Mariah_'s affection, and I did love his hands; Charlie is great (but then, Everett is always great), pretty witty Nell is a bundle of energy... The movie was so good, at the end my stomach was tight, my pulse was beating fast, and all I could do was... watch it again! :) As an actress's daughter, I had been curious about when and how did the transition between men-playing-women and women-playing-women. The how is perhaps romanticized, but... I am sure it was very hard on some men who were successful at it, and a personal angst did help drive that point through. The movie was honest, and the two Othelo death scenes which framed it quite took my breath away. The stylistic beauty of the first, where the traces of Comedia del'Arte could be observed, was stage beauty of one kind, and the long and winding path to the realistic stage beauty of the second one... made sense. The film is a strong acting one, where people who have serious connections with theater will get much more than the rest, which does distribute the real pith among a selected few. But there are also points which are more general - like s*x in pre-Victorian London (high) society, which was more relaxed than during and long after, and I thought that was represented very faithfully in the movie. Anyway, again, I loved the movie and I will definitely see it yet again!
Well the first time I saw this my first thought was... "Oh god no...". But as I watched it, it slowly became quite enjoyable. Even though I do feel like Stan's philosophies are a tad outdated and his idea of what a superhero is can get a bit one-dimensional, his challenges on the show do seem to bring out the best and worst qualities in the contestants. I really liked a lot of the twists and elimination results as the show progressed. The challenges too were original and entertaining. I found Stan's performance as a paternalistic guiding host very enjoyable. The contestants too just seem like really nice and entertaining people (although some of them are a bit dorky, or obviously trying to score some acting points on their resumes, and half of them probably wouldn't make the cut for narcissistic reality shows like A. Idol or Real World). I think the only part I didn't like (aside from the corniness, bad music, "reality" acting, and weirdness of the cast.) about the show was the costume remake. Sci-fi should have spent a bit more money on those costumes. It really says something that some of the originals looked better than what was given to them on the show. It gives the production values a real blow when you can't even afford a decent costume designer. Don't get me wrong though I liked the show, saw most of it in one night when Sci-Fi aired a bunch of episodes straight. (um... don't ask me why I was watching sci-fi... I um... was channel surfing)
First off let me start out by saying that I am not a huge Martin Lawrence fan. Big Momma's House 1 and 2 were pretty good for some dumb comedy movies (me owning the first one and liking it)but, National Security with Martin and Steve Zahn was passable. OK, now on to Rebound. Hot Head Basketball coach Roy McCormic (Lawrence) gets fired and loses his fame and decides to win the press and basketball league back by coaching a small middle school team called The Mt. Vernon Smelters. So he meets the kids, Keith, best player, One Love, loves shoes, hair and ego, Goggles, best spirit, always hit in the face, Ralph, two older brothers, lots of experience, and Fuzzy, the junk food addict (no offense). So bit by bit he starts to teach them to win and later they add two more players, Wes, the shy tall guy who Roy calls "The Sledgehammer", and Big Mac, the school bully who is not afraid of a fight. They get better and better and slowly make their way to victory. Some of the side joke adult characters such as the principal of the school (Meagan Mullaly of TV's "Will and Grace") and an over enthusiastic competitive coach (Patrick Warburton of (Kronk's New Groove). Overall I thought this movie was good and entertaining. It teaches a lesson to not be self centered. It was very sad in my opinion that the girl who played Big Mac died from a gunshot and was rumored to be in a gang. She would have become a "SuperSta". All and all very entertaining. 2 out of 4 stars
Excellent B-movie crime caper story with an A-movie complex twist pulled by the caper's Mr. Big, Preston Foster as Mr. "Foster"(how creative!). All the stereotypical movie bad/tough guys you love to hate are here...Jack Elam, Lee Van Cleef, and Neville Brand in typically bad guy roles, and all were tough and great and threatening. Hey, that must be what got them their reps! Suffice to say, Foster as Mr. Big had it all figured to take everything in the end with all the others involved in the caper losing out, that's all of the story I'll tell, but it played out quite tense in spots. John Payne was the good bad guy with exotic Collen Gray as "the love interest", stuck in the story more or less to make sure that romance-loving gals bought tickets too. Payne wore 3" lifts to get him up to John Wayne/Bob Mitchum height so he would look the hero part better and he puffed up to his full lift's height more than once when confronting the 3 Bad Men. He played his B-film Bob Mitchum role here pretty well, but Foster and the 3 Bad Men were the best things in the story with Foster the best of the bunch in his forceful and convincing role. Gray had only a small supporting role but really sparkled when she was flirting with "her man" of the future. One of the best B-noirs and right up there with most A's, but not up to the level of The Asphalt Jungle, The Killers, or Out of The Past. Those are the very best noirs, but this one is well worth seeing.
First-rate, outstanding, amazing storytelling & dialogs. What i dislike. 1.There were some plot inconsistencies as for me, mostly about languages they speak between races. (Well it's forgivable in the world of magic. And what a wonderful world!) 2.April is sometimes stupid and i didn't really like her as much as Zoe from sequel. 3.Resolution is obsolete (640x480?) even for 2000. 4.People you talk to are usually too forgetful. One example. Just half-a-minute ago the receptionist said i should disappear 'cause i'm not allowed in here, now he really believes April's a pizza-girl and lets me in... Strange. Then what i like. Well i like everything else. This is really a different story. No stupid narnias. I've found some references to World War II here. Dialogs are superb. Voices are perfect. Design is all well done. Sound is involving. Gameplay is non-active, but thanks to the story very interesting. I could run Journey all day long. We have the great ability of "skipping time" here. If you don't want to waste your precious time or fall asleep upon watching your April getting from one side of screen to another you just press escape several times and she gets where she's going in a few (real-time) seconds. This is one of my favorite fantasy worlds & stories: Ragnar Tornquist's world is inferior only to J.R.R. Tolkien's. And surely one of my favorite adventure games behind Grim Fandango (of course) and (i really love TLJ's sequel) Dreamfall: The Longest Journey.review_df = review_df.sort_values(by='neg', ascending=False)for i in range(5):
print(review_df['review'].iloc[i])If so, I think I didn't get it. It was somewhat entertaining, but hardly funny. I just couldn't have fun with these people. Half the characters were obnoxious, rude, abusive bastards, and the other half were ineffectual, incompetent, mumbling, pathetic losers, or sometimes a combination of the two. And yeah, I know that can be funny sometimes, but this wasn't the kind of bunch I wanted to spend two hours with. I didn't like them, I couldn't find them sympathetic, I couldn't relate to anyone, I couldn't understand why they loved each other so much, and in the end I couldn't help but feel that none of them deserved the luck they had (which was a lot in some cases). All they did was argue, shout, fight, fight again, fight some more, insult each other, do stupid stuff for no reason... It wasn't funny at all, it just got tiring after a while. And believe me, I am NOT squeamish about bad language, but I found that the amount of it in this film was just too much to put up with sometimes. They way the characters overused it made you dislike them even more. I never quite understood the craze for writer David Serrano's previous film, El Otro Lado de la Cama, which was a huge hit here in Spain, and seeing this didn't change my mind much: he's overrated. (One positive thing I will say: Alterio's impressive performance as the menacing, borderline psycho Antonio does raise an eyebrow or two. No wonder he got several nominations for Spanish awards)
"The Box" was not a good movie. I thought the main character, Frank, was a brutal thug just released from prison and destined to go back. He solves problems with violence and, as I saw it, stalked a waitress he met. I think the movie tried to portray Frank as a victim of circumstance where he tries to go straight but is pulled back into crime by the bad influences around him. It was not successful. Frank made deliberate choices to use violence while trying to recover money from the crime he was imprisoned for. Was I to believe that this action was justified and correct? I didn't buy it. It's the skewed logic of a criminal mind that since they stole something then it is now theirs and they are justified in using any means to recover their property. Hey, it's stolen property. It doesn't belong to you. Then there is the whole other story about the waitress and her dysfunctional relationship that Frank sticks his nose into. The whole movie had this poorly contrived aura about it. It seemed that there was an ending, a poor ending, the writer had in mind and he just filled in some facts in the beginning to get the ending to happen. The performances by the principles were poor. Theresa Russell is capable of far better work and she did an OK job given the poor story but overall it wasn't that great. Brad Dourif seemed like he wanted to portray a tough guy by cursing and acting like a fool. He wasn't believable. The movie was a waste of time. Don't bother with it.
Is it just me, or the last few seasons of E.R. haven't even been worth watching. Tragedy after tragedy, plot twist after plot twist. These are the most ill-lucked people in society. OK, so... Dr. Green has cancer, dies. O.K., I can run with that. Perfectly logical. Dr. Romano has his arm cut off at the elbow by a tail rotor. O.K., not likely, but if he happened to be in the wrong place at the wrong time...then maybe. But come on, then to get killed by the same chopped falling in a bloody fire on top of his head? Get real. Carter loses his baby, and his woman. Yawn. Hasn't the Carter family seen enough in the way of loss and rich people dilemmas? I am so sick of the "strong females" Abby doesn't want to marry Luka. Sam didn't want to marry Luka. Sam and her son. Again, and again, and again. Now for the love of god her crazy ex-husband kidnapped him and her both at gunpoint and they are driving somewhere along the Chicago interstate. Abby might lose her baby. Dr. Corday almost lost her baby. Dr. Weaver was in limbo with her son, after miscarrying. Dr. Benton had custody trouble. Dr. Lewis lost her niece. Can't these people hold on to their children? At least they did away with Dr. Lewis' sister. Man that chick fell off Ugly Mountian and hit every damn boulder on the way down. If anyone agrees...write to me to tell me so, then write to NBC to take this long-dead show off the air.
wow, i've seen something worse then cena's wrestling, his acting! wow....don't watch the marine...i went for the laugh factor of seeing cena play in a movie...but it wasn't worth it...they tried being funny, but quite frankly it was just pathetic....there were 43 explosions for crying out loud! bad acting anyone? when his wife thinks he dies, she doesn't even changer her facial expressions...she just shrugs it off like it's no big thing. a very very stupid plot....an ex marine goes to a gas station with his wife...but little does he know...some jewel thief's are in that exact same gas station! they steal his wife, need her as a hostage, though they didn't really....need a hostage at all. and they walk through a forest, while cena gets whacked in the head with a fire extinguisher and a plank of wood for the only laugh factors of the film. so we end off the film, with 20 explosions, and his wife chained up in a truck falling into a lake! and then...cena has an epic battle with the main villain everyone thought was dead! after 5 more explosions and much more crappy acting later, he beats him up and the whole place blows up with a huge explosion....he dives in for his wife....who is obviously dead at this point, brings her up, and saves her somehow....and in an ironic twist, john tritan says to his wife "shoulda gone to da beach" ohohohoh, hilarity ensued. i truly want my money back, plus some extra cash just for how bad it was
...I mean, besides the fact that it wouldn't be a short, snappy, catchy title. ;) Sleazy soap opera shenanigans? Reality show spoof? Serious murder mystery? Examination of the abuse of power and the tempting/corruption of innocents? Satirical jab at the rich & crazy and our famewhore culture? Sympathetic look at "poor" dysfunctional family? Envy the wealthy and ogle at the opulence! No, pity the rich their shallow, empty lives! What...the...hell. This show was all over the place. The tone, and apparent intent kept changing from episode to episode, depending on whoever was writing or directing that week, I guess. Looking at the list of credits (so many producers) it's easy to conclude that there were too many cooks in the kitchen...too many people who wanted a piece of the pie (mmm, now I'm hungry). Too many people behind the scenes who did not share a unified vision of what Dirty Sexy Money should be. Television, or any other kind of writing, by committee, sucks. Greedy, untalented hacks who attach themselves to a show they think will be a hit, also suck. They hired some damn fine actors for this thing (which is why I tuned in). Too bad TPTB didn't really know what to do with them, wasting their talent, and our time. I didn't even bother with Season 2, which I read was even more ridiculous. There's no way this incoherent mess could've ended to anyone's satisfaction. Just be glad it ended, freeing the cast for better work.Topic modeling
In topic modeling, the goal is to find groups of words which co-occur. These groups are called topics.
The classical approach for topic modeling is called Latent Dirichlet Allocation (Blei et al. 2003).
We will not consider the mathematical details, just the implementation.
References
- David M. Blei, Andrew Y. Ng, Michael I. Jordan. (2003). Latent Dirichlet Allocation Journal of Machine Learning Research. 3(Jan):993-1022.
Example: Associated Press
We consider 1085 Associated Press articles from here (Originally used in Blei et al. 2003).
from sklearn.decomposition import LatentDirichletAllocation
from sklearn.datasets import fetch_20newsgroupsap_files = os.listdir('../data/ap/')ap_list = []
for ap_file in ap_files:
with open('../data/ap/' + ap_file) as file:
ap_list.append(file.read())ap_list[0]"A new TV production company, Ventura Entertainment Group, entered the bidding Thursday for De Laurentiis Entertainment Group Inc., a movie-maker operating under the protection of federal bankruptcy court. Ventura Entertainment announced it had offered $35 million in cash and equity for De Laurentiis, which was founded by Italian filmmaker Dino De Laurentiis. Ventura Entertainment Chairman Harvey Bibicoff refused to disclose how much of the offer was in cash. At least three other entertainment companies have expressed interest in buying the assets of De Laurentiis, whose productions have included a remake of ``King Kong.'' A De Laurentiis spokesman referred questions about the bid to the company's investment banker, Oppenheimer & Co., whose Los Angeles office did not respond to requests for comment Thursday afternoon. Any transaction would require the approval of De Laurentiis creditors and the U.S. Bankruptcy Court. De Laurentiis, which lost $478,000 in the second quarter, filed for protection from its creditors under Chapter 11 of the federal Bankruptcy Code in mid-August. Ventura, an Encino-based public company, was formed six months ago by producer Irwin Meyer, former Columbia Pictures executive Stephen Girard and Bibicoff. Its only finished project is ``International Celebration of the Piano,'' a concert film for television. De Laurentiis' assets include North Carolina Film Studios in Wilmington, N.C., which is rented out for various productions; Onyx Entertainment, which holds the rights to various scripts, and United States rights to show the studio's library of 350 movies, including ``The Graduate'' and ``Carnal Knowledge.'' Other bidders divulged by the company are troubled moviemaker Cannon Group Inc., videodisk producer Image Entertainment Inc. and Atlantic Entertainment Group."# remove numbers
rm_num = re.compile(r'\d+(?:\.\d+)?')
for i, doc in enumerate(ap_list):
ap_list[i] = rm_num.sub('', ap_list[i])# convert list of docs to DTM
# argument min_df=10 ignores words in less than 10 docs
vectorizer = CountVectorizer(min_df=10, stop_words=stop_csv['word'].to_list())
dtm = vectorizer.fit_transform(ap_list)dtm.shape(1085, 3182)words = vectorizer.get_feature_names_out()X = dtm.toarray()We fit an LDA model. LDA is unsupervised - we pick how many topics we want the model to return (n_components).
np.random.seed(123)
lda = LatentDirichletAllocation(n_components=10)
lda.fit(X)LatentDirichletAllocation()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LatentDirichletAllocation()
The estimated topics are in lda.components_.
A topic is a distribution over the vocabulary. That is, topic k is:
\beta_k = (\beta_{k1}, \dots, \beta_{kV})
where \beta_{kv} is the probability of word v appearing in topic k.
beta = lda.components_
beta_norm = beta / beta.sum(axis=1)[:, np.newaxis]beta_df = pd.DataFrame(beta_norm, columns=words)We print the first 3 topics:
for i, row in beta_df.iterrows():
if i < 3:
print("topic", i, "--------------------")
print(row.sort_values(ascending=False).head(5))topic 0 --------------------
percent 0.044964
trade 0.010598
million 0.010097
billion 0.009550
prices 0.009237
Name: 0, dtype: float64
topic 1 --------------------
military 0.011966
government 0.011843
west 0.010283
east 0.009778
army 0.008767
Name: 1, dtype: float64
topic 2 --------------------
bush 0.020347
president 0.017838
dukakis 0.014388
campaign 0.008995
house 0.008696
Name: 2, dtype: float64from wordcloud import WordCloud
import matplotlib
cmap = plt.get_cmap('Paired')
cols = [matplotlib.colors.to_hex(c) for c in cmap.colors]
# Plot word clouds for each topic
for topic_idx, topic in zip(range(5), beta_norm):
plt.figure()
plt.title(f"Topic #{topic_idx + 1}")
# Create dictionary of word: weight
word_freq = {words[i]: topic[i] for i in topic.argsort()[:-6:-1]}
wordcloud = WordCloud(width=600,
height=300,
background_color='white')
wordcloud.generate_from_frequencies(word_freq)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()


Large language models
How does tokenization work in large language models? We want to allow for potentially new words we have never seen before.
A very simple tokenization we could to is to assign each unique character in the corpus with a number (corresponding to a one-hot encoding).
# here are all the unique characters that occur in this text
chars = sorted(list(set(jane_dict['prideprejudice'])))
vocab_size = len(chars)
print(''.join(chars))
print(vocab_size)
!"'()*,-.0123456789:;?ABCDEFGHIJKLMNOPRSTUVWYZ_abcdefghijklmnopqrstuvwxyz
75# create a mapping from characters to integers
stoi = { ch:i for i,ch in enumerate(chars) } # string to integer
itos = { i:ch for i,ch in enumerate(chars) } # integer to string
encode = lambda s: [stoi[c] for c in s] # encoder: take a string, output a list of integers
decode = lambda l: ''.join([itos[i] for i in l]) # decoder: take a list of integers, output a string
print(encode("hello there"))
print(decode(encode("hello there")))[56, 53, 60, 60, 63, 1, 68, 56, 53, 66, 53]
hello thereHowever, this approach can be very inefficient. Instead, many modern tokenizers use an algorithm such as byte pair encoding that greedily merges commonly occurring sub-strings based on their frequency.
Figure 12.8 from Understanding Deep Learning (Prince, 2024)
Here is a nice tool to see how different LLMs tokenize text.
Let’s input this text to Tiktokenizer:
Tokenization is at the heart of much weirdness of LLMs.
127 + 456 = 583
Apple.
I have an apple.
apple.
Apple.
for i in range(1, 101):
if i % 2 == 0:
print("hello world")Sentiment Analysis
Hugging face has many pre-trained large language models that we can use for sentiment analysis.
They also provide a sentiment analysis pipeline which:
- tokenizes the text
- passes the tokens through a model
- gets the sentiment score
First, install transformers (Hugging Face) and torch (Pytorch):
Terminal
pip install transformers torchThe default sentiment model is DistilBERT base uncased finetuned SST-2.
from transformers import pipeline
sentiment_pipeline = pipeline("sentiment-analysis")
data = ["I love you", "I hate you"]
sentiment_pipeline(data)No model was supplied, defaulted to distilbert/distilbert-base-uncased-finetuned-sst-2-english and revision 714eb0f (https://huggingface.co/distilbert/distilbert-base-uncased-finetuned-sst-2-english).
Using a pipeline without specifying a model name and revision in production is not recommended.
Device set to use mps:0[{'label': 'POSITIVE', 'score': 0.9998656511306763},
{'label': 'NEGATIVE', 'score': 0.9991129040718079}]review_scores_llm = []
for review in review_proc:
# the default can only take in strings ~400 characters
review_trunc = review[0:400]
score = sentiment_pipeline(review_trunc)
review_scores_llm.append({
'review': review,
'label': score[0]['label'],
'score': score[0]['score']
})llm_df = pd.DataFrame(review_scores_llm)pos_df = llm_df[llm_df['label']=='POSITIVE'].sort_values(by='score', ascending=False)
for i in range(5):
print(pos_df['review'].iloc[i][0:400])I loved this movie! Mistress Hughes is charming and true, Ned is perfect, I could well understand _Mariah_'s affection, and I did love his hands; Charlie is great (but then, Everett is always great), pretty witty Nell is a bundle of energy... The movie was so good, at the end my stomach was tight, my pulse was beating fast, and all I could do was... watch it again! :) As an actress's daughter, I
I have to say, that after thinking about it for awhile, I really enjoyed this movie. Its growing on me, even now.. It was visually stunning... really beautiful to look at. Of course, most Hindi films are really vivid, but this was exceptional, I think. Really well done by Santosh Sivan. If you are not a veteran of Hindi films, then you may not fully appreciate this movie... You kinda have to be u
This movie is an example of the kind of film that just can't be made anymore. At least not from a major studio. A compact, fast paced script that is based totally on character interaction. Ann Harding is cool as ice. Beautiful and smart, her character Joan Colby carry the film. William Powell doesn't have much to do except react to her, but he does it splendidly. He plays love interest John Fletch
These 3 stories are each so brilliant and wonderful... each in its own way. They describe what it was like to be gay in a small town in Connecticut in the 1950's, the 1970's, and in the year 2000. We see the hopelessness of the lesbian of the 50's - forced to move to Greenwich Village, and the torment of the perfect student/athlete of the 70's, who is nearly killed by his classmates for being gay.
Interviewed shortly before his death, the writer Dennis Potter identified the three of his works he considered the best: his serials 'Pennies From Heaven' and 'The Singing Detective', and this short play, in which he addresses childhood (and the memories thereof) by casting adults to play their younger selves. There's a great thematic consistency to all of Potter's writings, and it's easy in retroneg_df = llm_df[llm_df['label']=='NEGATIVE'].sort_values(by='score', ascending=False)
for i in range(5):
print(neg_df['review'].iloc[i][0:400])As a big fan of zombie movies and B-horror, I have come to expect enormous plot holes, sub-par editing, hard-not-to-laugh-at acting, and poor dialog. With these in mind I purchased Zombie Night from my local DVD/CD shop for 4$, why not add to the collection? What I didn't expect was that the acting would be SO bad that I would feel almost embarrassed watching and listening to these characters inte
"The Box" was not a good movie. I thought the main character, Frank, was a brutal thug just released from prison and destined to go back. He solves problems with violence and, as I saw it, stalked a waitress he met. I think the movie tried to portray Frank as a victim of circumstance where he tries to go straight but is pulled back into crime by the bad influences around him. It was not successful
wow, i've seen something worse then cena's wrestling, his acting! wow....don't watch the marine...i went for the laugh factor of seeing cena play in a movie...but it wasn't worth it...they tried being funny, but quite frankly it was just pathetic....there were 43 explosions for crying out loud! bad acting anyone? when his wife thinks he dies, she doesn't even changer her facial expressions...she j
I was not at all happy with the replacement of Ali McGraw with Jane Seymour; Jan Michael Vincent with Hart Bochner and some of the other changes. Thank God they left Robert Mitchum alone despite his age. I really missed John Houseman in his role as Aaron Jastrow and while I consider the late Sir John Gielgud to have been a superb actor, I kept looking for Houseman. Unfortunately his health prevent
The saying "sequels ain't equals" is definitely demonstrated in this completely lackluster follow-up to the earlier brilliantly witty "Fritz the Cat". While both films portray an anthropomorphic view of 70s counterculture using animals, and both use the shock value of drugs, sex and cursing to stir up a reaction; this movie by a totally different production team completely lacks any of the charm,