import requests
import bs4
import pandas as pdLecture 10 - Advanced Web Scraping
Overview
In this lecture, we cover more advanced web scraping with:
scrapyplaywright
References
This lecture contains material from:
The Document Object Model
From MDN Web Docs:
The Document Object Model (DOM) is the data representation of the objects that comprise the structure and content of a document on the web.
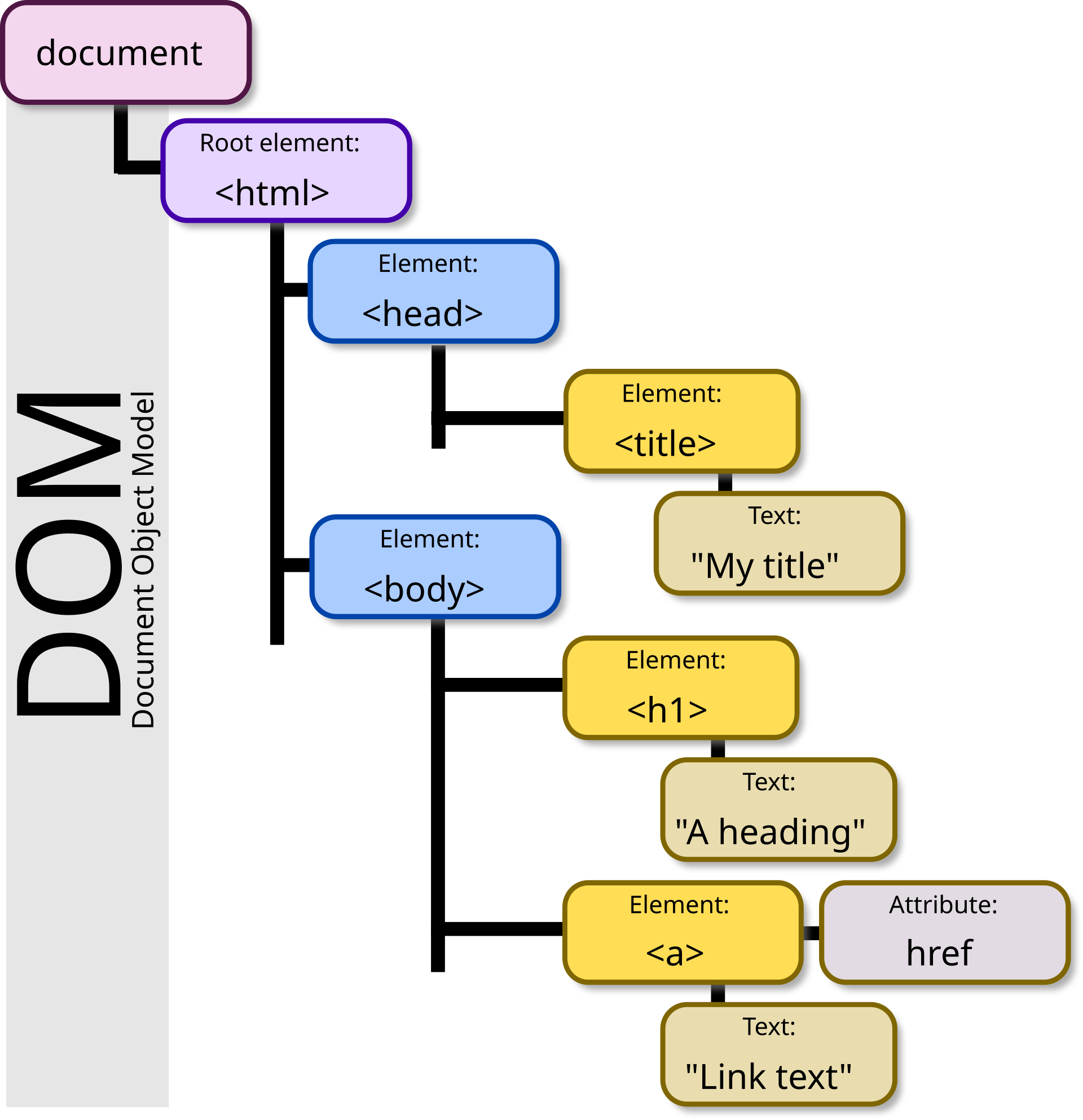
By Birger Eriksson - Own work, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=18034500
Review: Quotes
We are going to scrape https://quotes.toscrape.com, a website that lists quotes from famous authors.
We first scrape a single page of the quotes website using tools from last lecture. Then, we show how to automate scraping many pages with scrapy.
req = requests.get('https://quotes.toscrape.com')req<Response [200]>soup = bs4.BeautifulSoup(req.text, 'html.parser')quotes = soup.select("div.quote")print(quotes[0].prettify())<div class="quote" itemscope="" itemtype="http://schema.org/CreativeWork">
<span class="text" itemprop="text">
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”
</span>
<span>
by
<small class="author" itemprop="author">
Albert Einstein
</small>
<a href="/author/Albert-Einstein">
(about)
</a>
</span>
<div class="tags">
Tags:
<meta class="keywords" content="change,deep-thoughts,thinking,world" itemprop="keywords"/>
<a class="tag" href="/tag/change/page/1/">
change
</a>
<a class="tag" href="/tag/deep-thoughts/page/1/">
deep-thoughts
</a>
<a class="tag" href="/tag/thinking/page/1/">
thinking
</a>
<a class="tag" href="/tag/world/page/1/">
world
</a>
</div>
</div>
# tag: span, class: text
quotes[0].select("span.text")[<span class="text" itemprop="text">“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”</span>].select returns a list, so we need to select the first element and then get text via .text:
quotes[0].select("span.text")[0].text'“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”'# tag: small, class: author
quotes[0].select("small.author")[0].text'Albert Einstein'# tag: div, class: tags. > get children with tag: a, class: tag
[i.text for i in quotes[0].select("div.tags > a.tag")]['change', 'deep-thoughts', 'thinking', 'world']quote_list = []
for quote in quotes:
quote_list.append({'quote': quote.select("span.text")[0].text,
'author': quote.select("small.author")[0].text,
'tags': [i.text for i in quote.select("div.tags > a.tag")]})pd.DataFrame(quote_list)| quote | author | tags | |
|---|---|---|---|
| 0 | “The world as we have created it is a process ... | Albert Einstein | [change, deep-thoughts, thinking, world] |
| 1 | “It is our choices, Harry, that show what we t... | J.K. Rowling | [abilities, choices] |
| 2 | “There are only two ways to live your life. On... | Albert Einstein | [inspirational, life, live, miracle, miracles] |
| 3 | “The person, be it gentleman or lady, who has ... | Jane Austen | [aliteracy, books, classic, humor] |
| 4 | “Imperfection is beauty, madness is genius and... | Marilyn Monroe | [be-yourself, inspirational] |
| 5 | “Try not to become a man of success. Rather be... | Albert Einstein | [adulthood, success, value] |
| 6 | “It is better to be hated for what you are tha... | André Gide | [life, love] |
| 7 | “I have not failed. I've just found 10,000 way... | Thomas A. Edison | [edison, failure, inspirational, paraphrased] |
| 8 | “A woman is like a tea bag; you never know how... | Eleanor Roosevelt | [misattributed-eleanor-roosevelt] |
| 9 | “A day without sunshine is like, you know, nig... | Steve Martin | [humor, obvious, simile] |
How do we scrape multiple pages easily?? This is where scrapy is useful.
Scrapy Introduction
About
Scrapy is an framework for crawling web sites and extracting structured data.
Even though Scrapy was originally designed for web scraping, it can also be used to extract data using APIs.
Installation
First, install scrapy in your conda environment:
Terminal
pip install scrapyExample
This example follows the tutorial from the scrapy documentation.
- Create a new directory (i.e. folder) called
scrapy-project - In
scrapy-project, create a Python filequotes_spider.py - Copy the following code and paste in
quotes_spider.py:
python
import scrapy
class QuoteSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/',
]
def parse(self, response):
for quote in response.css("div.quote"):
yield {
'text': quote.css("span.text::text").get(),
'author': quote.css("small.author::text").get(),
'tags': quote.css("div.tags > a.tag::text").getall()
}
next_page = response.css("li.next a::attr(href)").get()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page)- Open your command line / Terminal, navigate to
scrapy-project, and run:
Terminal
scrapy runspider quotes_spider.py -o quotes.jsonl- When this finishes you will have a new file called
quotes.jsonlwith a list of the quotes in JSON Lines format, containing the text and author, which will look like this:
{"text": "\u201cThe world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.\u201d", "author": "Albert Einstein", "tags": ["change", "deep-thoughts", "thinking", "world"]}
{"text": "\u201cIt is our choices, Harry, that show what we truly are, far more than our abilities.\u201d", "author": "J.K. Rowling", "tags": ["abilities", "choices"]}
{"text": "\u201cThere are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.\u201d", "author": "Albert Einstein", "tags": ["inspirational", "life", "live", "miracle", "miracles"]}
...We can read in JSONL files with:
quotes = pd.read_json(path_or_buf='scrapy/quotes.jsonl', lines=True)
JSON vs. JSONL
JSON: the entire file is a valid JSON document
JSON example
{
"users": [
{"id": 1, "name": "Alice", "email": "alice@example.com"},
{"id": 2, "name": "Bob", "email": "bob@example.com"},
{"id": 3, "name": "Charlie", "email": "charlie@example.com"}
]
}JSONL: each line is a separate JSON object
JSONL example
{"id": 1, "name": "Alice", "email": "alice@example.com"}
{"id": 2, "name": "Bob", "email": "bob@example.com"}
{"id": 3, "name": "Charlie", "email": "charlie@example.com"}What just happened?
When you ran the command scrapy runspider quotes_spider.py, Scrapy looked for a Spider definition inside it and ran it through its crawler engine.
The crawl:
- Makes requests to the URLs defined in the
start_urlsattribute - Takes the HTML output and passes it into the
parsemethod. Theparsemethod:- Loops through the quote elements using a CSS selector
- Yields a Python dict with extracted quote text and author
- Looks for a link to the next page and schedules another request
We will go through the code in more detail in the section Scrapy Spiders.
Before we do that, however, we need a refresher of object oriented programming in Python.
Interlude: Object-Oriented Programming
Python is an object-oriented programming language.
Every item you interact with is an object. An object has a type, as well as:
- attributes (values)
- methods (functions that can be applied to the object)
As an example, 'hello' in Python is an object of type str, with methods such as split, join etc.
Classes
A Python class is a “blueprint” for an object.
We can define new classes. For example:
class Point:
""" Point class represents and manipulates x,y coords. """
def __init__(self, x=0, y=0):
""" Create a new point at the origin """
self.x = x
self.y = yAll classes have a function called __init__(), which is executed when the class is being initiated.
The self parameter is a reference to the current instance of the class, and is used to access variables that belong to the class.
Above, self.x=x means that each instance of the class has its own x value.
Let’s create an object p1 which is a new instance of the Point class:
p1 = Point(x=1.2, y=4)We can extract the x and y attributes of p1:
print(p1.x, p1.y)1.2 4We can also change attributes after the object has been created:
p1.x = 5
print(p1.x, p1.y)5 4Let’s re-write the Point class and add a method:
class Point:
""" Create a new Point, at coordinates x, y """
def __init__(self, x=0, y=0):
""" Create a new point at x, y """
self.x = x
self.y = y
def distance_from_origin(self):
""" Compute my distance from the origin """
return ((self.x ** 2) + (self.y ** 2)) ** 0.5p2 = Point(x=3, y=4)
p2.distance_from_origin()5.0Inheritance
Inheritance allows us to define a class that inherits all the methods and properties from another class.
# Parent class
class Animal:
def __init__(self, name):
self.name = name # Initialize the name attribute
def speak(self):
pass # Placeholder method to be overridden by child classes
# Child class inheriting from Animal
class Dog(Animal):
def speak(self):
return f"{self.name} barks!" # Override the speak method
# Child class inheriting from Animal
class Cat(Animal):
def speak(self):
return f"{self.name} meows!" # Override the speak method
# Creating an instance of Dog
dog = Dog("Buddy")
print(dog.speak())
# Creating an instance of Dog
cat = Cat("Puss")
print(cat.speak()) Buddy barks!
Puss meows!Scrapy Spiders
Spiders are classes which define how a certain site (or a group of sites) will be scraped.
Specifically:
- how to perform the crawl (i.e. follow links)
- how to extract structured data from their pages (i.e. scraping items)
Looking back at the beginning of the QuoteSpider class:
the first line indicates that
QuoteSpideris a new class inheriting from thescrapy.Spiderclass. Spiders require aname.class QuoteSpider(scrapy.Spider): name = "quotes" start_urls = [ 'http://quotes.toscrape.com/', ]The parent
scrapy.Spiderclass provides a defaultstart_requests()implementation which sends requests from thestart_urlsspider attribute and calls the spider’s methodparsefor each of the resulting responses.Now let’s consider the
parsecallback function. Theparsemethod is in charge of processing the response and returning scraped data and/or more URLs to follow.The first part of the function processes the response:
for quote in response.css("div.quote"): yield { 'text': quote.css("span.text::text").get(), 'author': quote.css("small.author::text").get(), 'tags': quote.css("div.tags > a.tag::text").getall() }- We can see this is similar to our BeautifulSoup processing:
quote_list = [] for quote in quotes: quote_list.append({'quote': quote.select("span.text")[0].text, 'author': quote.select("small.author")[0].text, 'tags': [i.text for i in quote.select("div.tags > a.tag")]})A difference is that in BeautifulSoup, to extract the text, we needed
.text. In Scrapy.css, we can use::textafter the CSS selector e.g.span.text::text.Notice also that we use
yieldinstead ofreturnfor the output. Unlike areturnstatement which terminates the function,yieldallows the function to produce values incrementally while maintaining its state.
The second part of the
parsefunction looks for a link to the next page and schedules another request.- In the HTML, we can see the next page link (
/page/2/) is in tagli, withclass='next':
<li class="next"> <a href="/page/2/">Next <span aria-hidden="true">→</span></a> </li>- In the
QuoteSpider, the following command extracts/page/2/, using::attr(href)to access thehrefattribute of<a>:
next_page = response.css("li.next a::attr(href)").get()- Then, this command creates the new URL to scrape, that is
https://quotes.toscrape.com/page/2:
next_page = response.urljoin(next_page)- Finally, we
yieldascrapy.Request:
yield scrapy.Request(next_page)- When you
yieldaRequestin theparsemethod, Scrapy will schedule that request to be sent and the resulting response will be fed back to theparsemethod.
- In the HTML, we can see the next page link (
Scrapy Shell
We can open an interactive scrapy shell to test our functions:
Terminal
scrapy shell 'URL'To exit the scrapy interactive shell, run exit.
Scrapy Example: Jazz Transcriptions
Single Page
We now use scrapy to get book titles and URLs from this website: https://blueblackjazz.com/en/books.
Workflow:
- Inspect the website HTML to figure out HTML tags and classes we want (potentially using SelectorGadget)
- Use scrapy shell to test our tags/classes and see what processing we need
Terminal
scrapy shell "https://blueblackjazz.com/en/books"
response.css('#body li a')
link = response.css('#body li a')[0]
link.css('::text').get()
link.attrib['href']jazz_single_page.py
import scrapy
class BookSpider(scrapy.Spider):
name = 'jazzspider'
start_urls = ['https://blueblackjazz.com/en/books']
def parse(self, response):
for link in response.css('#body li a'):
yield {'title': link.css('::text').get(),
'url': link.attrib['href'] }Terminal
scrapy runspider jazz_single_page.py -o jazz_data.csvMulti Page
The next spider clicks on the link for each transcription and extracts information from that link.
Before we run the spider, let’s see what the first link looks like:
response = requests.get('https://blueblackjazz.com/en/transcription/142/142-albert-ammons-12th-street-boogie-c-maj-transcription-pdf')
soup = bs4.BeautifulSoup(response.text, 'html.parser')elements = soup.select('h2.transcriptionTitle')elements[0].text'\nAlbert Ammons\n 12th Street Boogie\n \n C Maj\n\n - 5\n\n pages\n \n \n'We can clean up this string:
info = [i.strip() for i in elements[0].text.split('\n') if len(i.strip()) > 0]info['Albert Ammons', '12th Street Boogie', 'C Maj', '- 5', 'pages']We can also do the code checking in the scrapy shell.
jazz_multi_page.py
import scrapy
class BlogSpider(scrapy.Spider):
name = 'jazzspider'
start_urls = ['https://blueblackjazz.com/en/books']
def parse(self, response):
for link in response.css('div.row > div > ul > li > a'):
another_url = response.urljoin(link.attrib['href'])
yield scrapy.Request(another_url, callback=self.parse_transcription_page)
# callback specifies the function that will be called with first parameter being
# the response of this request (once it’s downloaded)
def parse_transcription_page(self, response):
for title in response.css('h2.transcriptionTitle'):
# this outputs a list
info = title.css('::text').extract()
# join the list
info = ' '.join(info)
info = [i.strip() for i in info.split('\n') if len(i.strip()) > 0]
yield {
'Musician': title.css('small::text').extract_first(),
'Title': info[1],
'Key': info[2],
'Pages': info[3].strip('- ')
}Terminal
scrapy runspider jazz_multi_page.py -o jazz_multi_data.csvScrapy Example: Hockey Teams
Now, let’s scrape the Hockey Team data from this site.
hockey.py
import scrapy
class HockeyTeamsSpider(scrapy.Spider):
name = "hockey_teams"
allowed_domains = ["scrapethissite.com"]
start_urls = ["https://www.scrapethissite.com/pages/forms/"]
def parse(self, response):
# Extract team data from the current page
for team in response.css('tr.team'):
yield {
'Team Name': team.css('td.name::text').get().strip(),
'Year': team.css('td.year::text').get().strip(),
'Wins': team.css('td.wins::text').get().strip(),
'Losses': team.css('td.losses::text').get().strip(),
'OT Losses': team.css('td.ot-losses::text').get().strip(),
'Win Percentage': team.css('td.pct::text').get().strip(),
'Goals For': team.css('td.gf::text').get().strip(),
'Goals Against': team.css('td.ga::text').get().strip(),
}
# Follow pagination links
next_page = response.css('a[aria-label="Next"]::attr(href)').get()
if next_page is not None:
next_page = response.urljoin(next_page)
yield response.follow(next_page, self.parse)Terminal
scrapy runspider hockey.py -o hockey_teams_data.csvScrapy Example: Books
A bookstore website http://books.toscrape.com/ has been built to learn web scraping.
We build a spider to click on each book URL and extract the info. There are 50 webpages of books, so start_urls is a list of 50 webpages.
We also write a new parse function for each page.
book_spider.py
import scrapy
class BookSpider(scrapy.Spider):
name = "toscrape-css"
start_urls = [
'http://books.toscrape.com/catalogue/page-%s.html' % page
for page in range(1, 51)
]
def parse(self, response):
for link in response.css("ol.row article.product_pod h3 a"):
# we can extract a shortened title with the following line, although this is shortened with (...) for long ones
link.css("::text").extract_first()
# url to an individual book page where complete information can be scraped
book_url = response.urljoin(link.attrib['href'])
yield scrapy.Request(book_url,
callback=self.parse_book)
def parse_book(self, response):
yield {
'title': response.css('div.product_main h1::text').extract_first(),
'price': response.css('div.product_main p.price_color::text').extract_first(),
'genre': response.css('li:nth-child(3) a::text').extract_first(),
'image_url': response.css('#product_gallery img::attr(src)').extract_first(),
'stars': response.css('div.product_main p.star-rating::attr(class)').extract_first().replace('star-rating ', '')
}Terminal
scrapy runspider book_spider.py -o bookstore.csvScrapy Advantages
- Requests are scheduled and processed asynchronously (scrapy doesn’t need to wait for a request to be finished, it can send another in the meantime)
- If a request fails or an error happens, other requests can keep going
Scrapy also gives you control over the “politeness” of your crawl, e.g. you can
- set a download delay between each request
- limit the amount of concurrent requests per domain
- use an auto-throttling extension that tries to figure out these settings automatically
Static vs Dynamic Websites
So far, we have been mostly looking at static websites.
Static websites serve pre-built HTML files directly to the browser:
- all content is present in the initial HTML response
- typically built with HTML, CSS and minimal JavaScript
We can use simple HTTP requests to obtain this content.
Dynamic websites generate content on-the-fly, often using JavaScript:
- initial HTML is minimal, with JavaScript loading content after page load
- content appears after JavaScript executes API calls
We need browser automation tools to extract this content because we must wait for JavaScript execution to finish. A popular automation framework is Playwright.
Before we discuss Playwright, however, we need to discuss asynchronous operations.
Interlude: Asyncio
Asyncio is a built-in Python library that us handle input-output processes more efficiently
The Problem: Many programs spend a lot of time just waiting - waiting for websites to respond, files to download, or databases to return results. During this waiting time, your CPU sits idle, doing nothing useful.
Traditional Approach: In regular Python code, operations happen one after another:
- Start operation A
- Wait for A to finish completely
- Only then start operation B
Asyncio Solution: Asyncio lets your program work on multiple tasks by switching between them when one is waiting:
- Start operation A
- When A needs to wait (like for a website to respond), temporarily pause it
- Start operation B during this waiting time
- Switch back to A when its data is ready
- Both operations finish faster than if done one after another
How It Works: Asyncio uses special functions called “coroutines” (defined with async def). Inside these functions, the await keyword marks spots where the function might need to wait. When your program hits an await, Python can temporarily switch to another task instead of sitting idle.
python
async def example_coroutine():
# pause here and come back to example_coroutine when f() is ready
r = await f()
return r
def example_function():
# this function only exits when f() has finished
r = f()
return fNote: You can only use await with awaitable functions.
Example: Traditional Approach
import time
start_time = time.time()
def fetch(url):
print(f'Starting {url}')
data = requests.get(url).text
print(f'Finished {url}')
return data
page1 = fetch('http://example.com')
page2 = fetch('http://example.org')
print(f"Done in {time.time() - start_time} seconds")Starting http://example.com
Finished http://example.com
Starting http://example.org
Finished http://example.org
Done in 0.2890596389770508 secondsExample: Asyncio Approach
Now let’s do the same thing, but asynchronously.
To do so, we need the package aiohttp (website)
Terminal
pip install aiohttpThis is because the requests.get(url) function is a synchronous (blocking) HTTP request function - it’s not designed to work with asyncio.
import aiohttp
import asyncio
import time
async def fetch_async(url, session):
print(f'Starting {url}')
async with session.get(url) as response:
data = await response.text()
print(f'Finished {url}')
return data
async def main():
async with aiohttp.ClientSession() as session:
# task1 = asyncio.create_task(fetch_async('http://example.com', session))
# task2 = asyncio.create_task(fetch_async('http://example.org', session))
# page1 = await task1
# page2 = await task2
page1, page2 = await asyncio.gather(
fetch_async('http://example.com', session),
fetch_async('http://example.org', session)
)
return page1, page2
start_time = time.time()
page1, page2 = await main()
print(f"Done in {time.time() - start_time} seconds")Starting http://example.com
Starting http://example.org
Finished http://example.com
Finished http://example.org
Done in 0.20457220077514648 secondsWhat is happening?
We define an
asyncfunction calledfetch_asyncthat:- Takes a URL and an
aiohttpsession - Makes an asynchronous HTTP GET request
- Returns the text content of the response
- Takes a URL and an
In the
main()function:We create a single aiohttp
ClientSession, which is specifically designed to work with asyncioWe start
task1andtask2usingasyncio.create_task()(this immediately begins the work)When
fetch_async()reachesawait response.text(), it pauses and lets the next runnable task continueAs soon as data arrives from one server, the corresponding task is resumed
We then await the tasks to collect their results:
page1 = await task1 page2 = await task2Alternative: the above steps can be simplified using
await asyncio.gather()
Note:
- Both requests run concurrently - we are not blocking the entire program while waiting for the response
- The
ClientSessionis properly managed using a context manager (i.e. awithstatement)
Asyncio in Jupyter Notebook
In Jupyter Notebook, to call an async function we can use await e.g.
out1, out2 = await main()If we were running Python in a Terminal, we would need to use:
out1, out2 = asyncio.run(main())Playwright
Playwright is an open-source testing and automation framework that can automate web browser interactions. It is developed by Microsoft.
With Playwright, you can write code that can open a browser. Then, your code can extract text, click buttons, navigate to URLs etc.
To install Playwright, activate your conda environment and run:
Terminal
pip install playwright
playwright installThe second command installs the browser binaries (Chromium, Firefox and Webkit).
Asynchronous vs Synchronous API
Playwright provides two distinct APIs in Python:
Synchronous API:
from playwright.sync_api import sync_playwright- Uses regular function calls
- Blocks execution until operations complete
Asynchronous API:
from playwright.async_api import async_playwright- Uses Python’s
async/awaitsyntax - Non-blocking execution
- Better performance
- Enables parallel operation of multiple browser tabs
- Uses Python’s
For Jupyter notebooks, you have to use the asynchronous API (otherwise you will get an error).
Example: Faculty Webpage
We first provide an example of Playwright and then we explain the code.
import asyncio
from playwright.async_api import async_playwright
async def scrape_faculty_data():
async with async_playwright() as p:
# Launch the browser and create a new context
browser = await p.chromium.launch(headless=False)
context = await browser.new_context()
# Create a new page within the context
page = await context.new_page()
# Navigate to the webpage containing the faculty list
await page.goto("https://statistics.rutgers.edu/people-pages/faculty")
# Wait for the content to load
await page.wait_for_load_state("networkidle")
# Initialize empty lists to store data
data = []
# Loop through all .newsinfo elements
faculty_items = await page.query_selector_all('.newsinfo')
for item in faculty_items:
# Extract data
name = await item.query_selector('span')
title = await item.query_selector('span.detail_data')
email = await item.query_selector('a[href^="mailto"]')
data.append({
'name': await name.text_content(),
'title': await title.text_content(),
'email': await email.text_content()
})
# Close the browser
await browser.close()
return pd.DataFrame(data)
faculty_df = await scrape_faculty_data()faculty_df| name | title | ||
|---|---|---|---|
| 0 | Pierre Bellec | Associate Professor | pcb71@stat.rutgers.edu |
| 1 | Matteo Bonvini | Assistant Professor | mb1662@stat.rutgers.edu |
| 2 | Steve Buyske | Associate Professor; Co-Director of Undergradu... | buyske@stat.rutgers.edu |
| 3 | Javier Cabrera | Professor | cabrera@stat.rutgers.edu |
| 4 | Rong Chen | Distinguished Professor and Chair | rongchen@stat.rutgers.edu |
| 5 | Yaqing Chen | Assistant Professor | yqchen@stat.rutgers.edu |
| 6 | Harry Crane | Professor | hcrane@stat.rutgers.edu |
| 7 | Tirthankar DasGupta | Professor and Co-Graduate Director | tirthankar.dasgupta@rutgers.edu |
| 8 | Ruobin Gong | Associate Professor | ruobin.gong@rutgers.edu |
| 9 | Zijian Guo | Associate Professor | zijguo@stat.rutgers.edu |
| 10 | Qiyang Han | Associate Professor | qh85@stat.rutgers.edu |
| 11 | Donald R. Hoover | Professor | drhoover@stat.rutgers.edu |
| 12 | Ying Hung | Professor | yhung@stat.rutgers.edu |
| 13 | Koulik Khamaru | Assistant Professor | kk1241@stat.rutgers.edu |
| 14 | John Kolassa | Distinguished Professor | kolassa@stat.rutgers.edu |
| 15 | Regina Y. Liu | Distinguished Professor | rliu@stat.rutgers.edu |
| 16 | Gemma Moran | Assistant Professor | gm845@stat.rutgers.edu |
| 17 | Nicole Pashley | Assistant Professor | np755@stat.rutgers.edu |
| 18 | Harold B. Sackrowitz | Distinguished Professor and Undergraduate Dire... | sackrowi@stat.rutgers.edu |
| 19 | Michael L. Stein | Distinguished Professor | ms2870@stat.rutgers.edu |
| 20 | Zhiqiang Tan | Distinguished Professor | ztan@stat.rutgers.edu |
| 21 | David E. Tyler | Distinguished Professor | dtyler@stat.rutgers.edu |
| 22 | Guanyang Wang | Assistant Professor | guanyang.wang@rutgers.edu |
| 23 | Sijian Wang | Professor and Co-Director of FSRM and MSDS pro... | sijian.wang@stat.rutgers.edu |
| 24 | Han Xiao | Professor and Co-Graduate Director | hxiao@stat.rutgers.edu |
| 25 | Minge Xie | Distinguished Professor and Director, Office o... | mxie@stat.rutgers.edu |
| 26 | Min Xu | Assistant Professor | mx76@stat.rutgers.edu |
| 27 | Cun-Hui Zhang | Distinguished Professor and Co-Director of FSR... | czhang@stat.rutgers.edu |
| 28 | Linjun Zhang | Associate Professor | linjun.zhang@rutgers.edu |
What just happened?
We use the asynchronous API
from playwright.async_api import async_playwrightWe define a function with
async:async def scrape_faculty_data(): async with async_playwright() as p: ...The syntax
async defdefines the functionscrape_faculty_dataas a “coroutine”The command
async with async_playwright() as p:returns an asynchronous context manager that initializes the Playwright library. On exit ofasync with, all remaining browsers are closed and resources are properly cleaned up.
We set up the browser, context and page:
browser = await p.chromium.launch(headless=False) context = await browser.new_context() page = await context.new_page()This initializes Playwright and creates a browser window (visible because
headless=False).Then,
browser.new_context()creates an isolated browsing environment (similar to an incognito window).Finally,
context.new_page()creates a new tab within a context.We navigate to the website and wait until all network activity stops i.e. the page is fully loaded
await page.goto("https://statistics.rutgers.edu/people-pages/faculty") await page.wait_for_load_state("networkidle")We extract data:
faculty_items = await page.query_selector_all('.newsinfo') for item in faculty_items: # ... extraction code ...query_selector_allreturns all elements that match selectorquery_selectorreturns the first element that matches the selector
Note: we can use
^to specify “starts with” e.g.a[href^="mailto"]selects thehrefattribute of tagathat starts with “mailto”.We store data in a list of dictionaries:
data.append({ 'name': await name.text_content(), 'title': await title.text_content(), 'email': await email.text_content() })We use
.text_content()to extract the text (similar to.textin BeautifulSoup).
Example: Jazz Transcriptions
Let’s look at a website where we need to use Playwright because the website is dynamically loaded.
https://www.blueblackjazz.com/en/jazz-piano-transcriptions/
First, we show that requests and BeautifulSoup can’t extract the table.
import pandas as pd
from bs4 import BeautifulSoup
import requests
url = "https://www.blueblackjazz.com/en/jazz-piano-transcriptions/"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
print(soup.find('tr').prettify())<tr class="small">
<th>
</th>
<th>
<a href="#searchFieldId" ng-click="sortBy='name';">
Sort by transcription name
</a>
</th>
<th>
<a href="#searchFieldId" ng-click="sortBy='artist';">
By artist
</a>
</th>
<th>
<a href="#searchFieldId" ng-click="sortBy='date';">
By date
</a>
</th>
<th>
<a href="#searchFieldId" ng-click="sortBy='note';">
By note
</a>
</th>
<th>
</th>
</tr>
Now, let’s try with Playwright.
First, let’s go to the website, right click on the table and select “Inspect Element”:
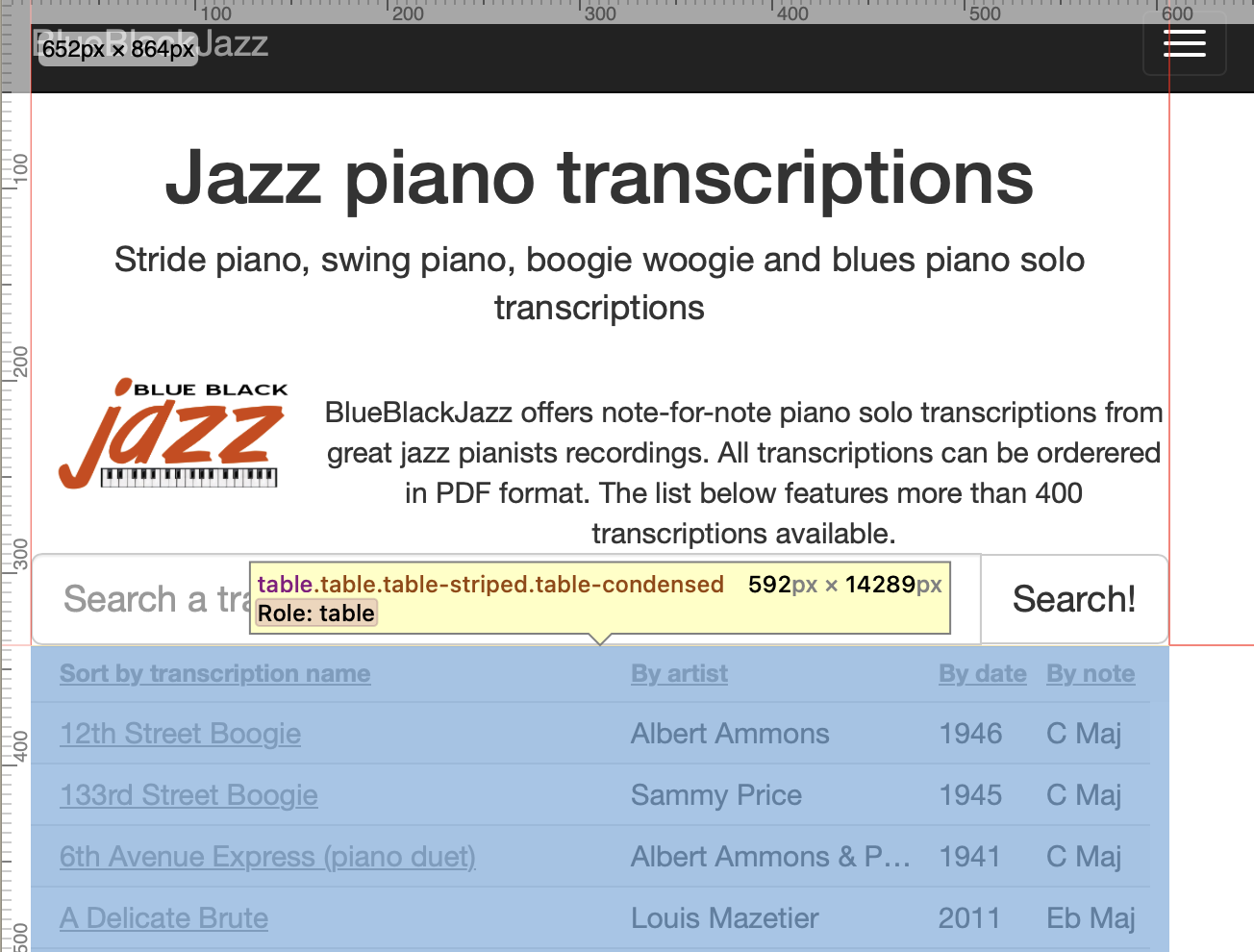
We can see the table is:
<table class="table table-striped table-condensed">This means there are three classes associated with <table> (table, table-striped, table-condensed).
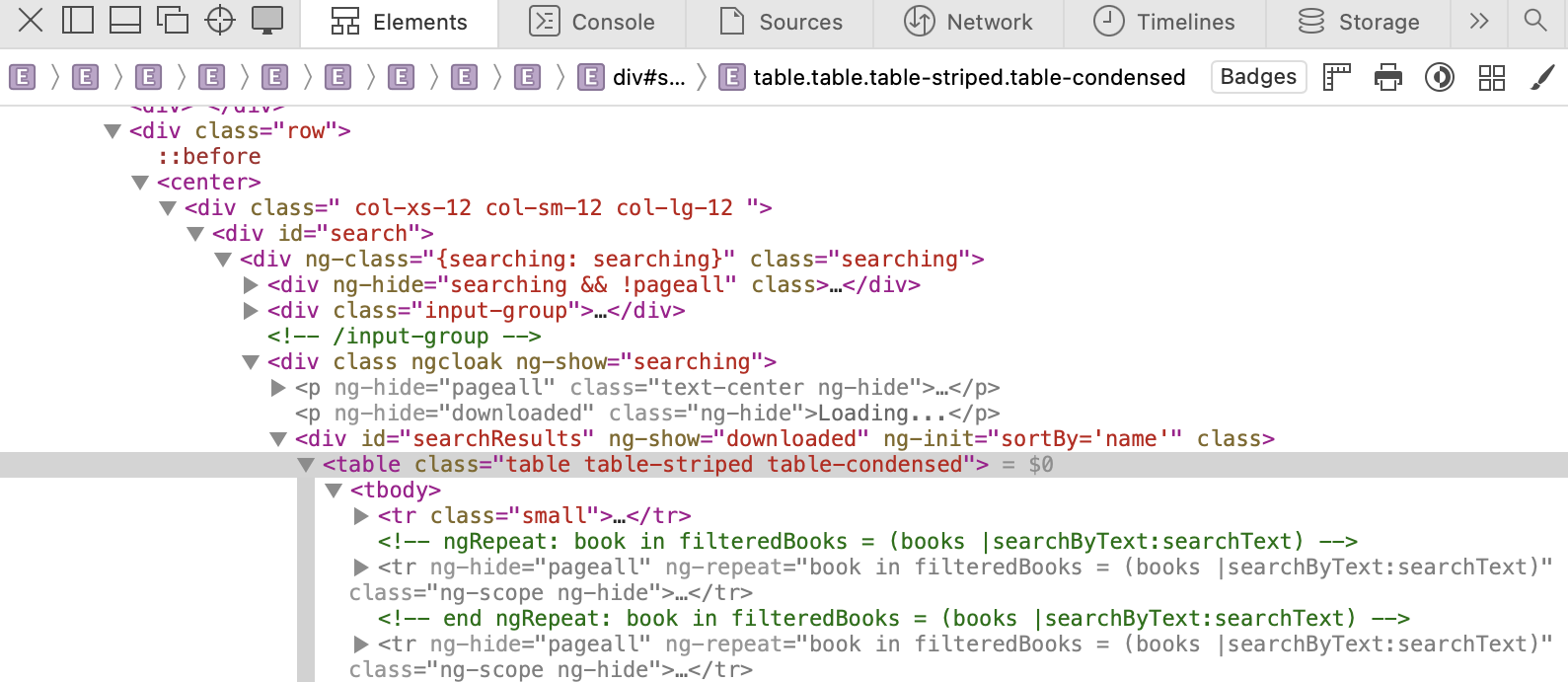
Then is another tag <tbody>, a child of <table>.
Finally, the info we are interested in is in <tr>, a child tag of <tbody> (see next image).
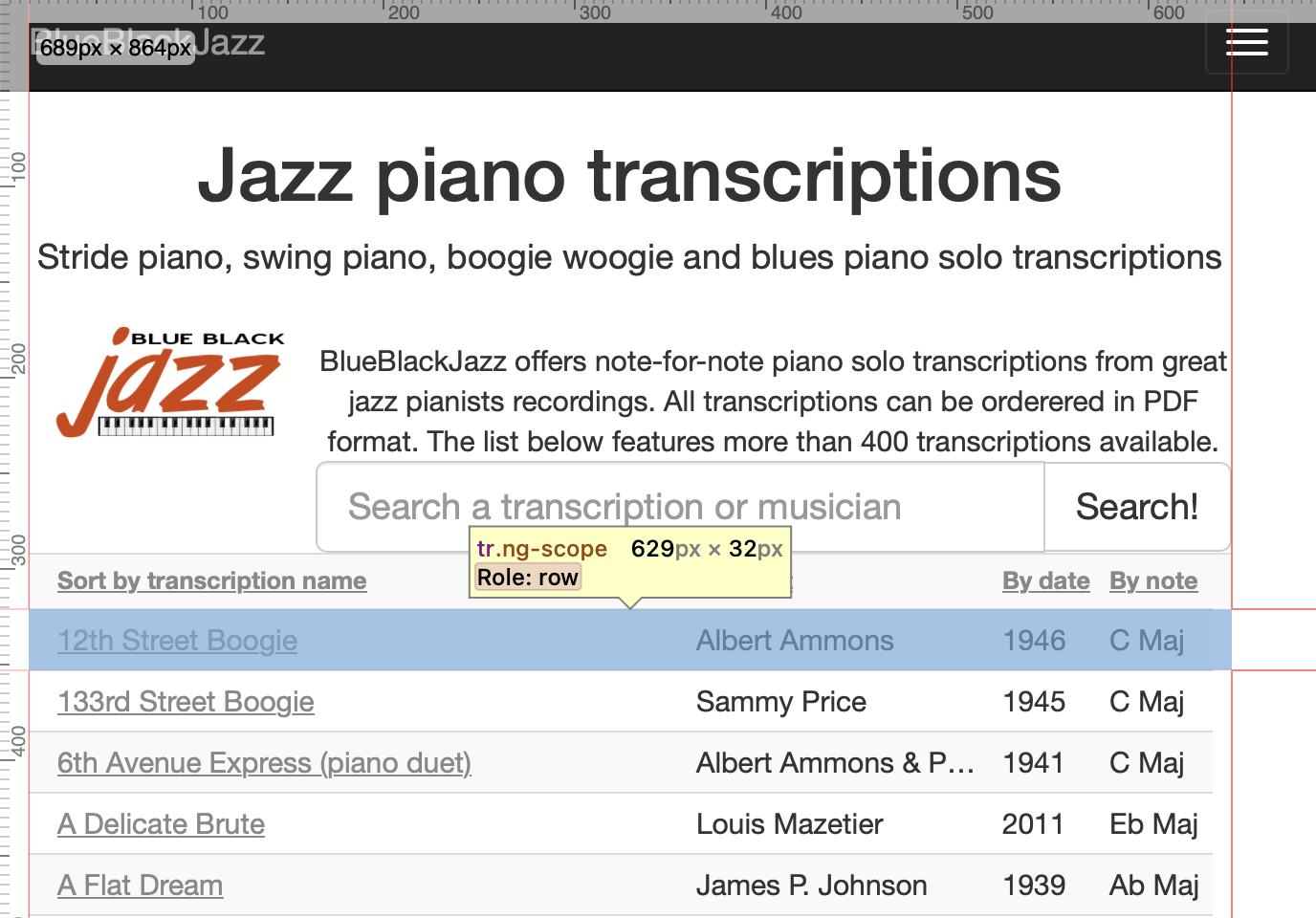
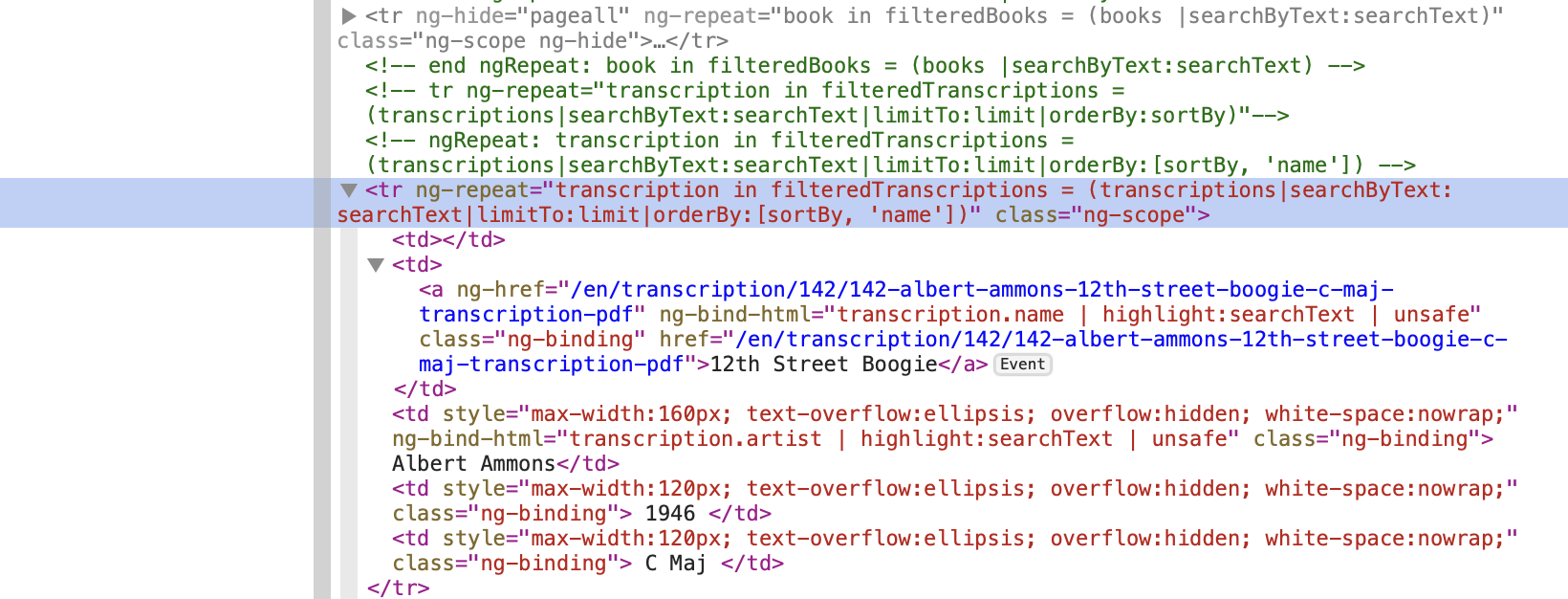
In <tr> with class="ng-scope":
- the second child has the title in the text (“12th Street Boogie”)
- the third child has the name in the text (“Albert Ammons”)
- the fourth child has the year in the text (“1946”)
- the fifth child has the key in the text (“C Maj”)
import pandas as pd
from playwright.async_api import async_playwright
async def scrape_jazz_data():
async with async_playwright() as p:
# Launch the browser and create a new context
browser = await p.chromium.launch()
context = await browser.new_context()
# Create a new page within the context
page = await context.new_page()
# Navigate to the webpage containing the list of transcriptions
await page.goto("https://www.blueblackjazz.com/en/jazz-piano-transcriptions/")
# Wait for the content to load
await page.wait_for_load_state("networkidle")
await page.wait_for_selector('.table.table-striped.table-condensed')
# Find all rows in the table
rows = await page.query_selector_all('.table.table-striped.table-condensed tbody tr')
transcriptions = []
for row in rows:
# Extract data from each row
cells = await row.query_selector_all('td')
if len(cells) > 4:
title = await cells[1].inner_text()
artist = await cells[2].inner_text()
date = await cells[3].inner_text()
note = await cells[4].inner_text()
transcriptions.append({
'title': title,
'artist': artist,
'date': date,
'note': note
})
await browser.close()
return pd.DataFrame(transcriptions)
jazz_df = await scrape_jazz_data()jazz_df| title | artist | date | note | |
|---|---|---|---|---|
| 0 | 20 Solos For Piano Volume 1 | Fats Waller | ||
| 1 | 20 Solos For Piano Volume 2 | Fats Waller | ||
| 2 | 20 Solos For Piano Volume 3 | Fats Waller | ||
| 3 | 17 Solos For Piano Volume 1 | James P. Johnson | ||
| 4 | 17 Solos For Piano Volume 2 | James P. Johnson | ||
| ... | ... | ... | ... | ... |
| 455 | You're Gonna Be Sorry | Fats Waller | 1941 | C Maj |
| 456 | You're My Favorite Memory | Teddy Wilson | 1946 | Eb Maj |
| 457 | You're the top | Fats Waller | 1935 | Eb Maj |
| 458 | Zig Zag | Willie "the Lion" Smith | 1949 | E min |
| 459 | Zonky | Fats Waller | 1935 | F min |
460 rows × 4 columns
.text_content() vs. .inner_text()
We have seen both .text_content() and .inner_text().
.text_content(): gets all text, including text hidden from display.inner_text(): gets just text diplayed as you would see in browser
Example: Quotes with Multiple Pages
Playwright can emulate browser actions, so we can “click” next to get to the next page:
import asyncio
from playwright.async_api import async_playwright
async def scrape_quotes():
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
await page.goto("https://quotes.toscrape.com")
all_quotes = []
while True:
quotes = await page.query_selector_all(".quote")
for quote in quotes:
text = await (await quote.query_selector(".text")).inner_text()
author = await (await quote.query_selector(".author")).inner_text()
all_quotes.append({
'text': text,
'author': author
})
next_button = await page.query_selector("li.next > a")
if next_button:
await next_button.click()
await page.wait_for_load_state("load")
else:
break
await browser.close()
return all_quotes
quotes = await scrape_quotes()Example: Quotes with Infinite Scroll
Using Playwright, we can also scrape websites that have dynamically loaded content accessed through scrolling down the webpage.
The website we consider is https://quotes.toscrape.com/scroll.
The logic is:
- scroll to bottom of the page
- count how many quote selectors there are
- scroll again
- check if there is a larger number of quotes, go to previous step
- if the number of quotes is constant for 3 scrolls, take that as total number of quotes
- process quotes
import asyncio
from playwright.async_api import async_playwright
async def scrape_quotes_scroll():
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
await page.goto("https://quotes.toscrape.com/scroll")
last_count = 0
same_count_repeats = 0
max_repeats = 3
while same_count_repeats < max_repeats:
# scroll from 0 (top of page) to bottom of page (document.body.scrollHeight)
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
await page.wait_for_timeout(3000) # wait for 3 seconds
quotes = await page.query_selector_all(".quote")
current_count = len(quotes)
if current_count == last_count:
same_count_repeats += 1
else:
same_count_repeats = 0
last_count = current_count
print(f"\nTotal quotes found: {len(quotes)}\n")
quote_list = []
for quote in quotes:
text = await (await quote.query_selector(".text")).inner_text()
author = await (await quote.query_selector(".author")).inner_text()
quote_list.append({
'text': text,
'author': author
})
await browser.close()
return quote_list
quotes = await scrape_quotes_scroll()
Total quotes found: 100
pd.DataFrame(quotes)| text | author | |
|---|---|---|
| 0 | “The world as we have created it is a process ... | Albert Einstein |
| 1 | “It is our choices, Harry, that show what we t... | J.K. Rowling |
| 2 | “There are only two ways to live your life. On... | Albert Einstein |
| 3 | “The person, be it gentleman or lady, who has ... | Jane Austen |
| 4 | “Imperfection is beauty, madness is genius and... | Marilyn Monroe |
| ... | ... | ... |
| 95 | “You never really understand a person until yo... | Harper Lee |
| 96 | “You have to write the book that wants to be w... | Madeleine L'Engle |
| 97 | “Never tell the truth to people who are not wo... | Mark Twain |
| 98 | “A person's a person, no matter how small.” | Dr. Seuss |
| 99 | “... a mind needs books as a sword needs a whe... | George R.R. Martin |
100 rows × 2 columns
Review: Wikipedia
We review scraping with requests and BeautifulSoup for a difficult scraping task. The goal is to scrape current events from Wikipedia.
import requests
import bs4
import pandas as pdurl = "https://en.wikipedia.org/wiki/Portal:Current_events/March_2025"
response = requests.get(url)soup = bs4.BeautifulSoup(response.text, "html.parser")We see the days have class="vevent".
days = soup.select('.vevent')Where is the date of each day?
print(days[0].prettify()[:390])<div aria-label="March 1" class="current-events-main vevent" id="2025_March_1" role="region">
<div class="current-events-heading plainlinks">
<div class="current-events-title" role="heading">
<span class="summary">
March 1, 2025
<span style="display: none;">
(
<span class="bday dtstart published updated itvstart">
2025-03-01
</span>
)
</span>
days[0].select('.bday.dtstart.published.updated.itvstart')[0].text'2025-03-01'The events themselves are in class="description".
events = days[0].select('.description')[0] # returns a list, need [0]print(events.prettify()[:1000])<div class="current-events-content description">
<p>
<b>
Armed conflicts and attacks
</b>
</p>
<ul>
<li>
<a href="/wiki/War_on_terror" title="War on terror">
War on terror
</a>
<ul>
<li>
<a href="/wiki/War_against_the_Islamic_State" title="War against the Islamic State">
War against the Islamic State
</a>
<ul>
<li>
<a href="/wiki/Islamic_State_insurgency_in_Puntland" title="Islamic State insurgency in Puntland">
Islamic State insurgency in Puntland
</a>
<ul>
<li>
<a href="/wiki/Puntland_counter-terrorism_operations" title="Puntland counter-terrorism operations">
Puntland counter-terrorism operations
</a>
<ul>
<li>
The
<a href="/wiki/Puntland_Dervish_Force" title="Puntland Dervish Force">
Puntland Dervish Force
</a>
captures an
<a href="/wiki/Islamic_State_%E2%80%93_Somalia_Province"Let’s see the categories:
categories = events.select('p')
categories[<p><b>Armed conflicts and attacks</b>
</p>,
<p><b>Arts and culture</b>
</p>,
<p><b>Disasters and accidents</b>
</p>,
<p><b>International relations</b>
</p>,
<p><b>Politics and elections</b>
</p>,
<p><b>Sports</b>
</p>]We can get direct children of events using .contents.
sub_events = events.contentsWe now can grab the events between the categories.
Let’s keep only the items that have no children items (these are the actual events, instead of their event sub-categories).
event_list = []
for sub in sub_events:
if isinstance(sub, bs4.element.Tag):
cat = sub.select('b')
if cat:
cat = cat[0].text
print(cat)
# if there are <li> tags in sub:
dat = sub.select('li')
if dat:
# Find all <li> tags that do NOT contain <li> children
leaf_lis = [
li for li in sub.find_all('li')
if not li.find('li')
]
# Print each leaf <li> and its cleaned-up text
for li in leaf_lis:
print('---', li.text)Armed conflicts and attacks
--- The Puntland Dervish Force captures an IS–Somalia base in Buqa Caleed, in the Cal Miskaad mountain range of Bari Region, Puntland, Somalia. (The Somali Digest) (Horseed Media)
--- United States Central Command says that it has carried out a precision airstrike in Syria, targeting and killing Muhammed Yusuf Ziya Talay, a senior military leader in Hurras al-Din. (Al Arabiya)
--- Three men are found dead in a vehicle near the village of Orú in the Tibú municipality, Norte de Santander, Colombia, with one body dressed in a National Liberation Army (ELN) uniform. (El Heraldo de Colombia)
--- After placing an ELN flag at the entrance of the municipality of Saravena, Arauca, the ELN detonate an improvised explosive device, targeting Colombian soldiers attempting to remove the flag. No casualties are reported. (El Heraldo de Colombia)
--- The first phase of the ceasefire between Israel and Hamas is scheduled to expire today while talks on the second phase, which aims to end the war, remain inconclusive. (DW)
--- Israel blocks the entry of all humanitarian aid from entering Gaza as the first phase of the ceasefire ends. (AP)
--- Civil society groups in the Ituri Province, Democratic Republic of the Congo, report that 23 people were killed and another 20 were taken hostage in raids by an Islamic State-affiliated faction of the Allied Democratic Forces militia over the past week. (Arab News)
--- The Kurdistan Workers' Party announces a ceasefire with Turkey after forty years of conflict. (Al Jazeera)
--- At least one person is killed and approximately nine others are wounded in the Druze-majority city of Jaramana, following armed confrontations between local residents and security forces affiliated with the transitional government. In response, the Suwayda Military Council declares a state of alert, while Israeli prime minister Benjamin Netanyahu and Defense Minister Israel Katz instruct the Israel Defense Forces to "prepare to defend" the city. (ANHA) (Times of Israel)
Arts and culture
--- At the 2025 Brit Awards, Charli XCX wins British Artist of the Year, while her album Brat wins British Album of the Year and her song "Guess" wins Song of the Year in collaboration with Billie Eilish. Ezra Collective wins Best British Group. (BBC News)
--- A group of winter swimmers in Most, Czechia, set a new world record for the largest polar bear plunge with 2,461 participants. The previous record was 1,799 participants set in Mielno, Poland, in 2015. (AP)
Disasters and accidents
--- At least 37 people are killed and 30 others are injured when two passenger buses collide near Uyuni, Potosí department, Bolivia. (BBC News)
International relations
--- Ukrainian president Volodymyr Zelenskyy meets with UK prime minister Keir Starmer in London, where they sign off on a British loan of GB£2.26 billion to buy military supplies for Ukraine. (BBC)
Politics and elections
--- Tens of thousands of demonstrators hold a rally in Bucharest, Romania, in support of presidential candidate Călin Georgescu and demand that the second round of the annulled 2024 election is held instead of a new election. (AP)
--- United States President Donald Trump signs an executive order designating English as the country's official language. (The Guardian)
--- Yamandú Orsi and Carolina Cosse are inaugurated as the president and vice president of Uruguay in Montevideo. (Reuters)
--- Italian nun Raffaella Petrini is sworn is as President of the Pontifical Commission for Vatican City State and President of the Governorate of Vatican City State, becoming the first woman to assume one of the highest political offices in the Vatican. She succeeds Spanish cardinal Fernando Vérgez Alzaga. (RTVE)
Sports
--- At their annual general meeting in Northern Ireland, the International Football Association Board approves a new rule stating that beginning the following season, if a goalkeeper holds the ball for more than eight seconds, the opposing team is awarded a corner kick. (BBC)Now, let’s put all this together.
days = soup.select('.vevent')
all = []
for day in days:
date = day.select_one('.bday.dtstart.published.updated.itvstart').text
events = day.select_one('.description')
sub_events = events.contents
for sub in sub_events:
if isinstance(sub, bs4.element.Tag):
if sub.select('b'):
cat = sub.select_one('b').text
# if there are <li> tags in sub:
if sub.select('li'):
# Find all <li> tags that do NOT contain <li> children
for li in sub.find_all('li'):
if not li.find('li'):
all.append({'date': date,
'category': cat,
'event': li.text})march = pd.DataFrame(all)
march| date | category | event | |
|---|---|---|---|
| 0 | 2025-03-01 | Armed conflicts and attacks | The Puntland Dervish Force captures an IS–Soma... |
| 1 | 2025-03-01 | Armed conflicts and attacks | United States Central Command says that it has... |
| 2 | 2025-03-01 | Armed conflicts and attacks | Three men are found dead in a vehicle near the... |
| 3 | 2025-03-01 | Armed conflicts and attacks | After placing an ELN flag at the entrance of t... |
| 4 | 2025-03-01 | Armed conflicts and attacks | The first phase of the ceasefire between Israe... |
| ... | ... | ... | ... |
| 434 | 2025-03-31 | International relations | The United States announces sanctions on six C... |
| 435 | 2025-03-31 | International relations | The Moldovan foreign affairs ministry expels t... |
| 436 | 2025-03-31 | International relations | Newly elected Prime Minister of Greenland Jens... |
| 437 | 2025-03-31 | Law and crime | A court in Abu Dhabi, United Arab Emirates, se... |
| 438 | 2025-03-31 | Law and crime | National Rally politician Marine Le Pen is con... |
439 rows × 3 columns
Conclusion
We have considered a number of different approaches to web scraping with Python:
requestsfor HTTP requests andBeautifulSoupfor parsing HTMLscrapyPlaywright
When to use what?
In general:
Static HTML, simple tasks
✅ requests and BeautifulSoup are good for quick scrapes
✅ scrapy is very efficient
❌ Playwright can be overkill (and slow)
Static HTML, multiple pages, large scale
❌ requests and BeautifulSoup are slow
✅ scrapy is very efficient
❌ Playwright can be slow (runs a browser)
Javascript-rendered content, interactivity
❌ requests and BeautifulSoup
❌ scrapy
✅ Playwright