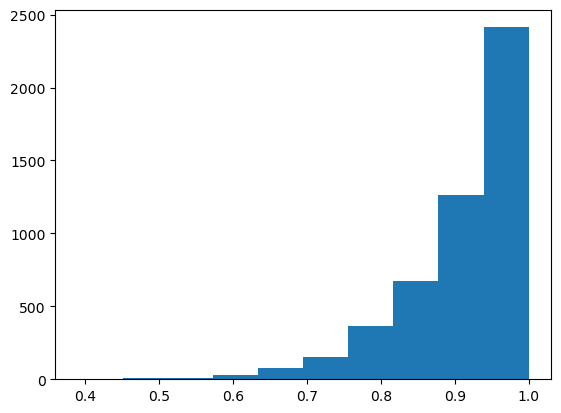
This simulation shows that we only get (1-\alpha)-coverage ON AVERAGE over the calibration set. That is, if we fix the calibration set, our coverage is not guaranteed.
Below, we see the distribution of coverages for a fixed calibration set of size 10.
import numpy as npimport matplotlib.pyplot as pltfrom scipy.stats import beta# ParametersN =10# Total number of variablesnprob =1000# samples to estimate coverage probabilityndraw =5000# estimating beta distributionalpha =0.1preds10 = np.zeros((ndraw, nprob))for i inrange(ndraw): preds = []# fixed calibration set observed_variables = np.random.normal(0, 1, N)# quantile of fixed calibration set qhat = np.quantile(observed_variables, np.ceil((1-alpha) * (N+1)) / N)for j inrange(nprob):# Generate the N-th random variable new_variable = np.random.normal(0, 1, 1)# is this variable in the prediction set??? preds10[i, j] = (new_variable < qhat)
/var/folders/f0/m7l23y8s7p3_0x04b3td9nyjr2hyc8/T/ipykernel_4161/1945614140.py:27: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
preds10[i, j] = (new_variable < qhat)
# each row corresponds to a fixed calibration setplt.hist(preds10.mean(1))
If you average over the calibration sets, we recover (1-\alpha) coverage.
preds10.mean()
0.9108314
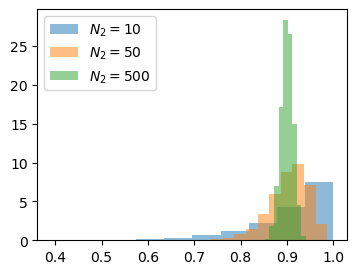
If we increase the size of our calibration set, the coverage probabilities are closer to (1-\alpha) (for a fixed calibration set.)
# ParametersN =50# Total number of variablesnprob =1000# Number of simulationsndraw =5000alpha =0.1preds50 = np.zeros((ndraw, nprob))for i inrange(ndraw): preds = [] observed_variables = np.random.normal(0, 1, N) qhat = np.quantile(observed_variables, np.ceil((1-alpha) * (N+1)) / N)for j inrange(nprob):# Generate the N-th random variable new_variable = np.random.normal(0, 1, 1) preds50[i, j] = (new_variable < qhat)
/var/folders/f0/m7l23y8s7p3_0x04b3td9nyjr2hyc8/T/ipykernel_4161/3492330592.py:23: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
preds50[i, j] = (new_variable < qhat)
# each row corresponds to a fixed calibration setplt.hist(preds50.mean(1))
# ParametersN =1000# Total number of variablesnprob =1000# Number of simulationsndraw =5000alpha =0.1preds1000 = np.zeros((ndraw, nprob))for i inrange(ndraw): preds = [] observed_variables = np.random.normal(0, 1, N) qhat = np.quantile(observed_variables, np.ceil((1-alpha) * (N+1)) / N)for j inrange(nprob):# Generate the N-th random variable new_variable = np.random.normal(0, 1, 1) preds1000[i, j] = (new_variable < qhat)
/var/folders/f0/m7l23y8s7p3_0x04b3td9nyjr2hyc8/T/ipykernel_4161/2919383409.py:23: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
preds1000[i, j] = (new_variable < qhat)