import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
import scipy
from scipy.stats import t
from scipy.stats import ttest_1samp
torch.manual_seed(42)<torch._C.Generator at 0x12351c3f0>import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
import scipy
from scipy.stats import t
from scipy.stats import ttest_1samp
torch.manual_seed(42)<torch._C.Generator at 0x12351c3f0>Let’s toss a coin 10 times.
sample = np.random.binomial(10,0.5)sample3Let’s repeat this 10,000 times.
How many times will we see 10 heads and 0 tails?
nsim = 10000
nheads = np.zeros((nsim))
for i in range(nsim):
sample = np.random.binomial(10,0.5)
nheads[i] = sampleplt.hist(nheads);
sum(nheads == 0)np.int64(7)If we do enough tests, we will see rare things, even when the null hypothesis is true!
How do we account for this?
We run one-sample t-tests for m hypotheses.
We do the following corrections:
n = 40 # number of samples
m = 1000 # number of features
X = np.random.normal(size = (n, m))
#h0 is trueX[:, 0]array([ 1.5313092 , 0.53290643, -0.20507263, -0.21943257, 1.41259982,
1.56706395, -0.5560178 , -0.15096074, 2.22095752, 0.25092368,
1.27136647, 0.55787479, 1.37460293, 2.3379473 , 1.03916608,
1.71483632, 1.10433825, 1.0101977 , 0.08367518, 1.01190298,
0.72651405, 0.95938617, 0.16123895, -1.04333106, -1.00011848,
-1.30946954, -0.86537489, 1.51199718, -0.0579648 , -1.60297809,
0.64446901, -1.77507243, 0.72951869, -0.4199296 , 0.38631833,
2.54361033, -0.72546776, -1.55101337, -0.00686815, 0.08269307])plt.scatter(range(m), X.mean(axis=0))
def ttest_1(x, h0_mean=0):
df = n-1
mean = x.mean() # sample mean x_bar
d = mean - h0_mean # x_bar - mu (mu=0 under H_0)
v = np.var(x) # sample variance
denom = np.sqrt(v / n) # variance of sample mean
tstat = np.abs(d / denom)
# xmean - h0_mean / (sqrt(var/n))
# our test-stat is a t distributed random variable with n-1 degrees of freedom
pval = t.cdf(-tstat, df = df) + (1 - t.cdf(tstat, df = df))
# pval - probability in the lower and upper tails of our t distribution
return pvalpvals = np.zeros((m))
for j in range(m):
pvals[j] = ttest_1samp(X[:, j], 0).pvalue# no multiple testing correction
# we expect to reject m * 0.05 samples
alpha = 0.05
nmp = np.where(pvals < alpha)[0]
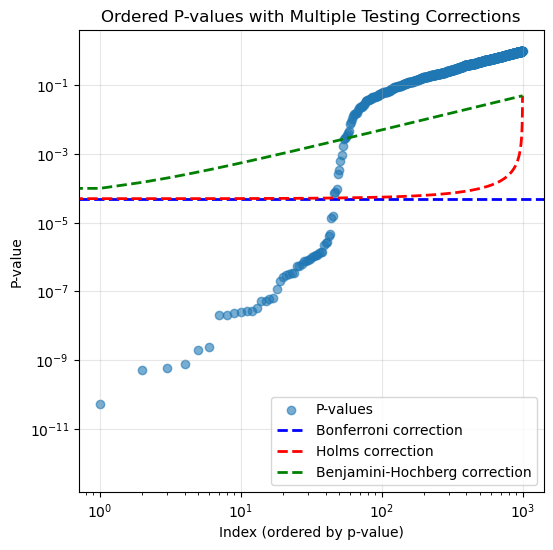
print("No multiple testing correction: reject ", nmp.shape[0])No multiple testing correction: reject 49# bonferroni
bf = np.where(pvals < alpha/m)[0]
print("Bonferroni: reject ", bf.shape[0])Bonferroni: reject 0# holms
ord_pvals = np.argsort(pvals)
holms = []
for j, s in enumerate(ord_pvals):
#j = 0, s is index of smallest p-val
denom = m - j
if pvals[s] <= (alpha/denom):
holms.append(s)
else:
break
print("Holms: reject ", len(holms))Holms: reject 0# BH procedure # this is different from holms and bonferroni in that
# we control FDR, not FWER
q = 0.05
bh = []
for j, s in enumerate(ord_pvals):
val = q * (j + 1) /m # zero indexing
if pvals[s] <= val:
bh.append(s)
else:
break
print("Benjamini-Hochberg: reject ", len(bh))Benjamini-Hochberg: reject 0plt.figure(figsize=(6, 6))
plt.scatter(range(m), pvals[ord_pvals], alpha=0.6, label='P-values')
plt.axhline(y=alpha/m, color='b', linestyle='--', label='Bonferroni correction', linewidth=2)
# Holms correction line
holms_threshold = alpha / (m - np.arange(m))
plt.plot(range(m), holms_threshold, 'r--', label='Holms correction', linewidth=2)
# Benjamini-Hochberg correction line
bh_threshold = (alpha / m) * (np.arange(m) + 1)
plt.plot(range(m), bh_threshold, 'g--', label='Benjamini-Hochberg correction', linewidth=2)
plt.xlabel('Index (ordered by p-value)')
plt.ylabel('P-value')
plt.legend()
plt.yscale('log')
plt.xscale('log')
plt.title('Ordered P-values with Multiple Testing Corrections')
plt.grid(True, alpha=0.3)
plt.show()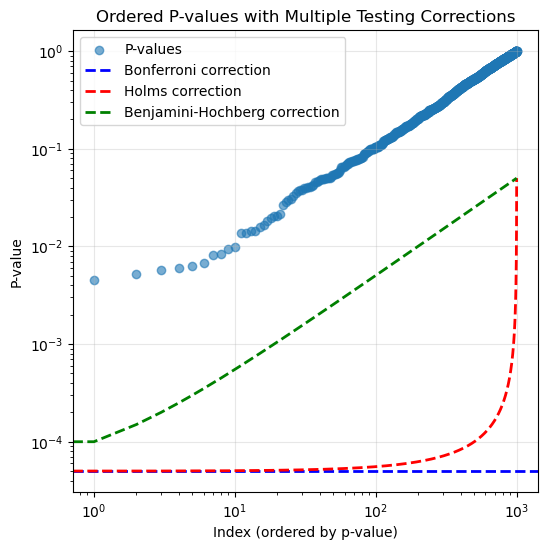
true_mean = np.array([1.0] * int(m*5/100) + [0] * int(m * 95/100))
X = np.random.normal(size = (n, m))
X = X + true_mean
plt.scatter(range(m), X.mean(axis=0))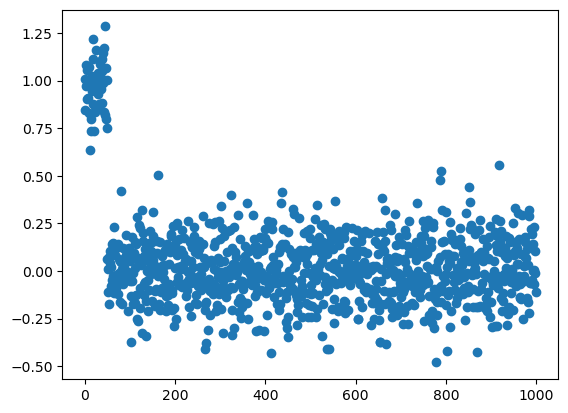
print('Number of hypotheses we should reject: ', int(m * 5/100))Number of hypotheses we should reject: 50pvals = np.zeros((m))
for j in range(m):
pvals[j] = ttest_1samp(X[:, j], 0).pvalue# no multiple testing correction
alpha = 0.05
nmp = np.where(pvals < alpha)[0]
print("No multiple testing correction: reject ", nmp.shape[0])No multiple testing correction: reject 100# bonferroni
bon = np.where(pvals < alpha/m)[0]
print("Bonferroni: reject ", bon.shape[0])Bonferroni: reject 46
# holms
ord_pvals = np.argsort(pvals)
holms = []
for j, s in enumerate(ord_pvals):
denom = m - j
if pvals[s] <= (alpha/denom):
holms.append(s)
else:
break
print("Holms: reject ", len(holms))Holms: reject 47# BH procedure
q = 0.05
bh = []
for j, s in enumerate(ord_pvals):
val = q * (j + 1) /m # zero indexing
if pvals[s] <= val:
bh.append(s)
else:
break
print("Benjamini-Hochberg: reject ", len(bh))Benjamini-Hochberg: reject 56plt.figure(figsize=(6, 6))
plt.scatter(range(m), pvals[ord_pvals], alpha=0.6, label='P-values')
plt.axhline(y=alpha/m, color='b', linestyle='--', label='Bonferroni correction', linewidth=2)
# Holms correction line
holms_threshold = alpha / (m - np.arange(m))
plt.plot(range(m), holms_threshold, 'r--', label='Holms correction', linewidth=2)
# Benjamini-Hochberg correction line
bh_threshold = (alpha / m) * (np.arange(m) + 1)
plt.plot(range(m), bh_threshold, 'g--', label='Benjamini-Hochberg correction', linewidth=2)
plt.xlabel('Index (ordered by p-value)')
plt.ylabel('P-value')
plt.yscale('log')
plt.xscale('log')
plt.legend()
plt.title('Ordered P-values with Multiple Testing Corrections')
plt.grid(True, alpha=0.3)
plt.show()